AI新知力系列
統計學本質和架構筆記 - 105無母數可以變成有母數
什麼無母數?無母數分析?在統計學裡分為有母數分析和無母數分析。前者就是佔最大多數的統計學比例,後者大概就兩三章左右。那所謂的母數指的是母體參數。所謂的無母數就是沒有母體,沒有母體參數。但我們還要做數據分析,所以發展了無母數分析。這在我大學和研究所時期非常盛行,研究所考試年年都考。
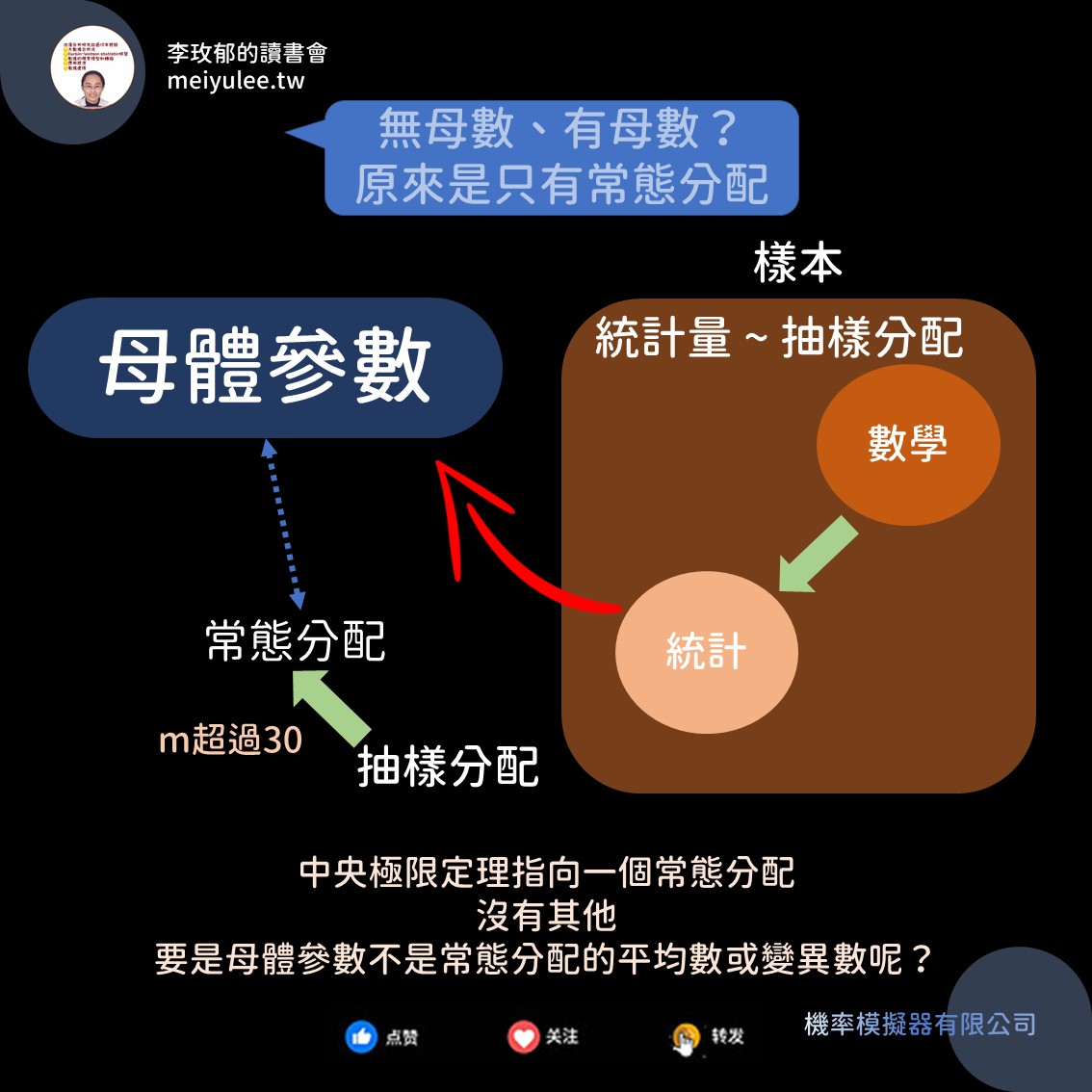
不過,我今天要分享的是統計學就是有母數,無母數的出現是因為樣本統計分析的假設:常態分配。
如果你還沒看過前4篇筆記,可以先複習一下喔。
101《認識統計學的兩大板塊》
102《了解統計學兩大板塊關係》
103《機率分配參數代表母體特性》
統計分析的前提假設:常態分配
原本統計學的母體和母體分配是有各種的分配,每個機率分配就會有不同的參數,像常態分配是平均數和變異數;柯西分配是中位數和平均絕對離差;指數分配的參數是λ;雙倍指數分配的參數是μ和λ,還有更多的機率分配(見下圖)。
可是到了樣本的統計量後,統計量要指向母體參數,而統計分析所用的統計量就是平均數和變異數。你不會看到統計量是中位數,因為建立不出中位數的抽樣分配。也不會看到統計量是平均絕對離差,同樣的理由:沒有抽樣分配。
那你能做什麼?
整套的統計分析都是圍繞著常態分配的兩個參數在討論,建立的分析方法。 如果母體不是常態分配,母體參數就不是平均數和變異數。那麼統計量也得配合母體參數,並且還得有對應的抽樣分配,才能進行統計分析(點估計、區間估計、假設檢定)。
於是,這就是我們看到的統計分析的整套分析方法是基於常態分配而建立的。如果不是常態分配,那全都叫做「無母數」的範疇。

結語
無母數分析的出現就是為了解決樣本來自非常態分配的母體時總要有解決的辦法,它因此而生。如果我們可以為非常態分配的平均數和變異數以外的統計量,找到抽樣分配,就如我長期研究的 Durbin-Watson 序列相關統計量,在2013年之前從未出現過它的抽樣分配。
當統計量有其對應的抽樣分配時,才能繼續統計分析的點估計、區間估計和假設檢定。那你可能會想兩個問題:
- 我怎麼知道母體參數不是常態分配的平均數和變異數呢?
- 我怎麼為統計量找到對應的抽樣分配呢?
第一個問題正是現在數據挖掘(Data mining)、大數據分析和人工智慧一直想要得到的分析技術。因為要從數據中得到數據特徵和數據規律,並且還能被分析。正如我第一篇《101認識統計學的兩大版塊》內提到的機率為統計之母,機率分配知道,那就沒有統計的事情了。而解決之道在於卡方檢定分析中的「適合度檢定」方法。此方法就是幫助樣本檢定出來自何種母體分配。但如果這樣的方法足夠了,這世界和技術進步也就不會是現在的樣子。
第二個問題則是落在機率分配模擬器的技術上。這點我得分享一下我投稿英國期刊的經驗。這期刊不接受來自其他模擬器的數字模擬。其實數字模擬有兩種,可以從Excel上發現。第一種方法就是直接用Excel內建的函數,出來的數字非常完美,沒有隨機性問題。第二種方法是來自《Excel calculating the probability distribution simulated data》從均勻分配轉換出各種的機率分配,每個分配的數字有隨機特性。