大數據和人工智慧方法中的建模方法,你用對了嗎?想評估用對與否得先對數據分析流程有所了解。我將介紹數據分析的完整流程。當然這很可能後面又會被我改善(笑),基礎的架構仍不會改變。
1.為什麼要談數據分析流程
數據分析是從數據當中汲取出數據的規律性,形成數學模型,並且可驗證此數學模型和反覆模擬的沙盒。目前的數據分析問題來自:
- 無法為數據找到正確的機率分配
- 變數(或稱為變數)間的關聯通常只有線性模型,非線性模型最多4次方,再高次方被稱為overlapping
- 嶺迴歸方法只是將自變數的斜率盡可能壓到1以下並接近0,影響性幾近消失,全由不可控的殘差完成螺旋狀的逼近,無法得到數據的數學模型
- 大數據分析和人工智慧方法皆無驗證之法
所以這篇文章將提供如何建構大數據分析方法的流程。這其中將包含統計學的測定機率分配(來自機率分配模擬器1及適合度檢定)、假設檢定(隨機性及自我相關)、迴歸建模、驗證模型(機率分配模擬器及強大數法則)。
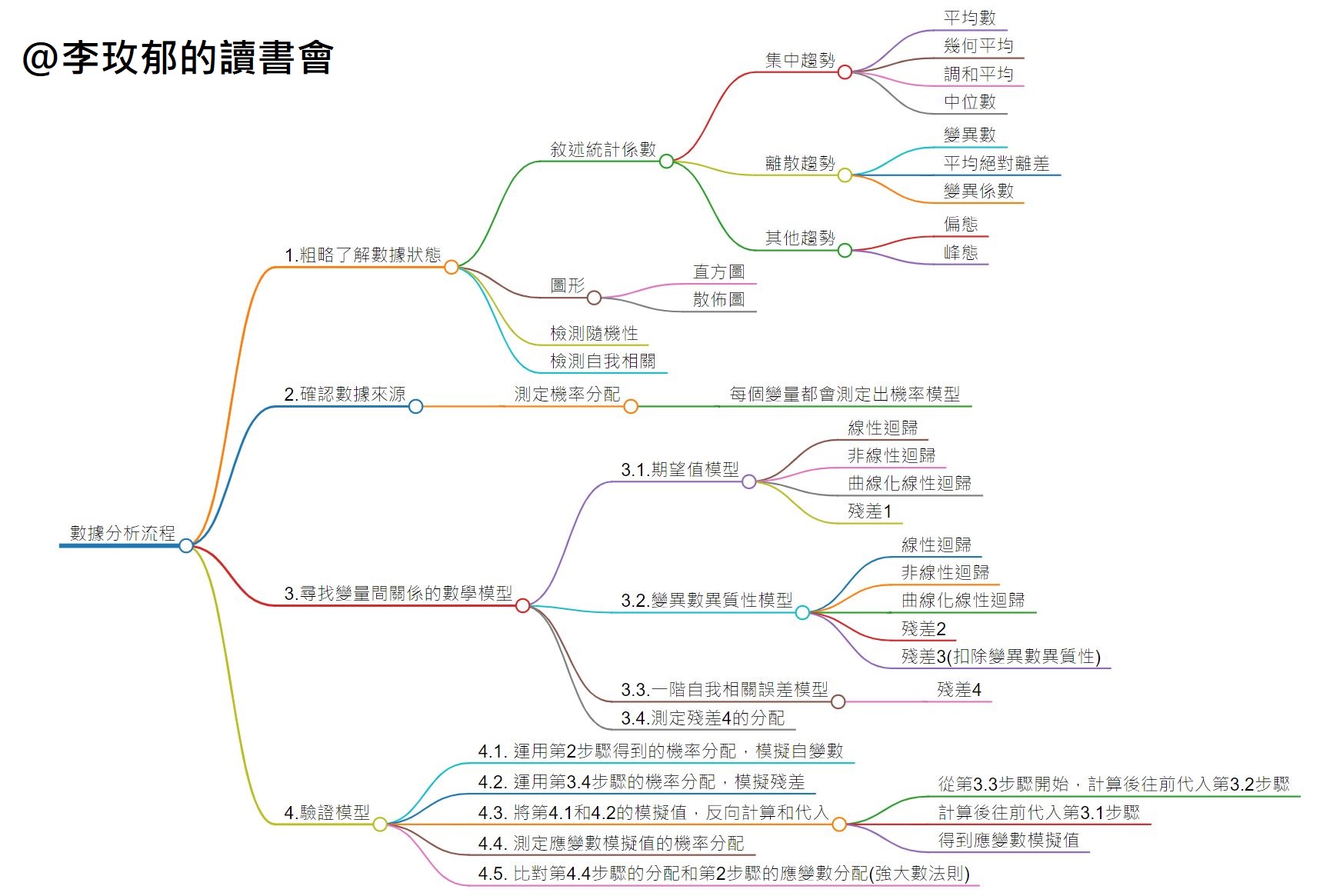
2. 詳解數據分析流程
第1步:粗略了解數據狀態
第一步我們要先對數據有所了解。這也是目前大數據和人工智慧達到的層次:觀察、分類、判斷。在第一步當中,可以分為三大項目:
-
敘述統計係數
敘述統計學的係數和圖形是統計學教科書最基礎的內容,有的在國中和高中就開始教授。這裡我跟隨課本對係數的分類有:
- 集中趨勢:集中趨勢代表數據的「中心位置」。因為數據帶有隨機性,但多數的數據會有集中一起的特性,形成數據的位置。常用的係數有:
- 離散趨勢:這是以數據的位置為中心,看數據分散的程度。常用的係數有:
- 變異數
- 優點:可以讓遠離數據的「平均數」的距離更明顯看出
- 缺點:分配未必存在平均數
- 平均絕對離差
- 優點:維持一次方的距離、可以用平均數或中位數當中心位置
- 變異係數
- 優點:可知道每單位平均數分攤的離散程度、適合不同數據的離散程度比較
- 變異數
- 其他趨勢
- 偏態係數了解分配的型態
- 峰態了解數據的分配多集中在中心位置
- 圖形: 圖形的顯示可以讓人直觀發現數字的規律。不過數據量大,或者數據的變數之間沒有明顯關係時,很難發現數字規律。這是現行常見使用的數據「圖像視覺化」。
- 直方圖
- 散佈圖
- 其他圖形
- 檢測:一組數據或一個變數的數據有什麼特性呢?我們可以使用統計學的隨機性檢定和自我相關檢定了解數據滿足統計需要的數字特性。
2.確認數據來源
當我們粗略了解數據狀態後,每組數據或一個變數的數據就可被測定來源。數據的來源指的是「機率分配」(Probaility distribution)。得到的機率分配又可稱為機率模型。
想要找出數據的機率分配的第一步: 你需要先知道有哪些機率分配在你的軟體或程式資料庫內。這是數據分析使用的模型之基礎模板。你沒有這些基礎模板,又如何去做測定呢?另外也有很多的大數據或人工智慧方法需要設定「事前機率」,這來自於特定的機率分配。又回到本段落最開始,你需要先知道有哪些機率分配在你的軟體資料庫內。
想要找出數據的機率分配的第二步: 資料庫內的機率分配數量足夠嗎? 有的軟體或程式內建不到10種機率分配做模擬,有的則達25個機率分配。但這樣就足夠嗎?數據分析師最怕的就是數據來源無法被正確地確定!因為我們要和資料庫內的數據分配進行比對,所以你的數據分配數量不夠,很難找出數據來源。當然也有些數據根本不是來自單純的機率分配,而是 「組合式的機率分配」,這將會到第3步驟去找尋出來。
想要找出數據的機率分配的第三步: 適合度檢定或曲線配適測定方法。為什麼我只用適合度檢定,使用皮爾森卡方檢定統計量的適合度檢定足夠讓我們測定出數據的機率分配,而且還包含機率分配的參數。
所有統計學方法的目的就是找出機率分配的參數!目前常被統計學者或數據分析家使用的軟體或程式中,即使測定數據的機率分配,也只能測定來自哪個機率分配,無法知道參數值6 (例外7)。
第一步和第二步需要機率分配模擬器的幫助,才能在進行第三步時,除了找出數據的機率分配外,並能找到機率分配的參數。我會在另外的文章中介紹「機率分配模擬器」和註腳7的「建模軟體」。
3.尋找變數間關係的數學模型
統計的迴歸分析是很好的尋找變數間數學模型的方法。傳統的統計迴歸分析專注討論「期望值模型」的「線性迴歸」。你可以加入很多的自變數,也可以讓自變數和應變數變成分類型變數。不過迴歸分析對數字的基本要求為「具備數字的累加性」,所以迴歸分析並不適合用於分類型變數上。我在這邊不討論數字是否具備累加性,而是分享變數間的數學模型搭配迴歸分析可以做到的精確模型方法。
我們將自變數和應變數的數學關係以$Y=f(X)$表示,$Y$ 為應變數,$X$ 為自變數且可以有很多的自變數。此時,我們不知道 $f(\bullet)$ 的形式。傳統迴歸分析都是假設線性:$Y=\beta_{0}+\beta_{1}X+\varepsilon$,$\beta_{0}$ 為截距;$\beta_{1}$ 為斜率;$\varepsilon$ 為誤差;$Y$ 的期望值為 $E(Y)=\beta_{0}+\beta_{1}X$。
但數據間的關係真只有線性嗎?如果線性無法解釋,模型的錯誤和原本數據的誤差都會進入$\varepsilon$。有些方法轉換數據特性,將線性迴歸的斜率壓低到接近0,如此一來就全心解構誤差即可。你覺得這樣的方法有問題嗎?
當然有問題!自變數變成為了建構線性迴歸的「工具人」!你選擇哪個變數當「自變數工具人」都可以,用完就丟。這些個方法主要就是討論誤差,至於電腦跑這些方法的演算法如何搞定誤差?你這個使用者不用關心,只需知道結果的預測能力很好就行!你不覺得很可笑嗎?
我們既然要找出變數間的關係,就要能夠顯示出 $f(\bullet)$ 的形式。下表提供使用者們了解迴歸分析方法建模的基本架構8。
| 模型 | 3.1. 期望值模型 |
3.2. 變異數異質性模型 |
3.3. 一階自我相關模型 |
|---|---|---|---|
| 線性迴歸 | ☑ | ☑ | ☑ |
| 非線性迴歸 | ☑ | ☑ | |
| 曲線化線性迴歸 | ☑ | ☑ | |
| 其他變化型 | ☑ | ☑ | |
| 殘差 | 殘差1 (傳統迴歸分析的殘差) |
殘差2 殘差3(扣除變異數異質性) |
殘差4 (號稱乾淨的殘差) |
3.1. 期望值模型
迴歸分析方法建立精確的模型需要經過4個過程,如表格上標示的3.1~3.3。3.1為迴歸分析方法最基本的核心建模。迴歸分析本就是為了確認條件常態分配平均數參數的情況,所以迴歸分析就是找期望值函數的方法,礙於函數形式過於複雜時,迴歸係數的點估計量很難找出點估計量的特性和其抽樣分配。在有總比沒有好的心態下,3.1.期望值模型只有線性迴歸。
事實是你可以弄出非線性迴歸,也可以跑曲線化線性迴歸(Curvilinear regression),甚至是其他函數的轉換。你該選哪個函數形式做為期望值模型呢?
所有模型跑完後的判定條件:MSE最小
當你確定函數形式,就可得到殘差,$e=Y-(\hat{\beta_{0}}+\hat{\beta_{1}}X)$。這些殘差可以計算MSE,還能繼續解構殘差。
影響殘差的因素來自傳統迴歸分析的基本假設:同質變異數、無相關,所以殘差可解構成兩部分:變異數異質性模型和一階自我相關誤差模型。
3.2. 變異數異質性模型
我們無法保證數據滿足「同質變異數」特性,即使用變異數異質性檢定,也是在期望值模型為線性迴歸下得到的檢定統計量。做了檢定,不代表能有效消除掉變異數異質性。過去我在學習變異數異質性時,總覺得這些方法都是依據「猜測」和「經驗」,而非一套有邏輯且有判斷準則的方法。檢定後,就只有那兩三種方式扣除變異數異質性影響,從不直球對決數據的變異數異質性問題,從而真正解決變異數異質性。
事實上,變異數異質性的其中一個成因來自「錯誤的期望值模型」。所以第一個數據分析的建模流程為什麼要先做期望值模型,並且要盡可能精確的理由就在這。這使得殘差相對比只有線性迴歸的方法還要乾淨。接著才能討論變異數異質性模型。
同樣建模方式,設定變異數異質性模型的函數:$e_{t}=H(X)+new error$。我們要找出 $H(\bullet)$ 的形式。如上表的第二欄,可以建立那麼多的迴歸方程式,挑出MSE最小的結果,做為變異數異質性模型。
要進入3.3的殘差,不是使用新殘差,而是要將3.1的殘差扣除3.2的變異數異質性才是新殘差。相關的作法請直接看註腳8的論文。
3.3. 一階自我相關誤差模型
能夠進入3.3的殘差是已經扣除變異數異質性後的殘差。這裡只有一階自我相關誤差,$e_{t}=\rho \times e_{t-1} + \phi_{t}$。$\hat{\rho}$ 的估計量使用Durbin-Watson統計量代入。
於是,我們就有三條數學方程式,還有最後一階自我相關誤差模型得到的殘差(稱為殘差4)。
殘差4的機率分配使用第2步驟的測定機率分配方法,就可得到殘差4的機率分配。這可做為第4步驟驗證時模擬使用。
4.驗證模型
建模完成後,自然要驗證。單純回測不足以支撐整個模型驗證的完整性,還要進行超過千萬次的模擬,確認模型的準確性(Accurancy and precision)。但取得的數據集常常是開放性資料,只是數據當中一部分而已。再加上人的精力有限,所以使用電腦做到人類做不到的程度可謂是「人工智慧」的另一種呈現。
目前的研究方法通常是基於設計的演算法做「訓練樣本」,這些演算法看似來自數學,卻無法顯示數據規律的數學方程式。更多的情況是沒有驗證,起因在於沒有辦法驗證,以及沒有驗證工具。而我說的數據分析的架構流程卻已經建構出控制在最小誤差下產生數據的數學方程式。這點在驗證過程中更能突顯歸因狀態和尋找異常狀態。有任何問題發生時,可以從數據的數學方程式找出問題點。
在第4步驟下,我們需要進行以下的子步驟。
- 4.1. 運用第2步驟得到的機率分配,模擬自變數
- 4.2. 運用第3.4步驟的機率分配,模擬殘差
- 4.3. 將第4.1和4.2的模擬值,反向計算和代入
- 從第3.3步驟開始,計算後往前代入第3.2步驟
- 計算後往前代入第3.1步驟
- 得到應變數模擬值
- 4.4. 測定應變數模擬值的機率分配
- 4.5. 比對第4.4步驟的分配和第2步驟的應變數分配(強大數法則)
這些子步驟都是根據前面的第2和第3步驟得到的結果才能進行驗證數學模型產生的模擬值。另外,第4.4步驟還可延伸變成完全使用自變數和應變數之模擬值進行模型的係數計算。每次1億筆成對隨機樣本,計算得到一組迴歸係數,包含3.1、3.2、3.3的係數。重複動作1億次,即可建立係數的抽樣分配。
係數抽樣分配加上自變數和應變數、殘差的機率分配即可完成數據模型沙盒(Sandbox)。
5. 小結
完整的數據分析流程走完一次後,就可以寫入大數據和人工智慧的模塊中,有新的數據進入就能夠跑一次,得到最小誤差下數據的數學方程式、完整的數據模型沙盒。大數據和人工智慧皆基於數據規律和判定方法,建構出應用端的使用。一套分析流程不外乎從input到output,事後驗證等項目,我這在歸納出大數據和人工智慧需要的數據分析完整流程,讓建模時可降低誤差至最小、如何找出數字規律的數學方程式,以及完成建模後如何驗證。
學習知識是循序漸進的,不外乎先建立基本的分析架構,然後再填充細枝末節或重要枝幹的理論進去。我提的這套數據分析流程是基於數學和統計分析的理論知識,整合在一起得到的。以後你遇到有人說數據分析,或用演算法來和你交流學習時,這個數據分析流程可提供你抓出他們的問題點,例如,你為什麼用線性模型?你顯示預測結果的圖形非常棒,那數據的數學方程式可以顯示給我看嗎?你為什麼不用非線性迴歸呢?你只有檢定變異數異質性確認存在,為什麼你要除以X的平方,而不是其他函數型態呢?各種的問題你都可向正在跟你交流的人提出問題或剛好你在學習就可以提出質疑。
參考資料
-
數學模擬、統計軟體或程式都需要機率分配模擬,其基礎來自亂數。大多數的軟體或程式已經內建資料庫,直接使用指令呼叫,造成內建的機率分配種類不多,也無法做其他功能,例如函數轉換。機率分配模擬為高階的模擬軟體技術,2021年已經被公開出書,可使用MicroSoft Office Excel做觀念的基礎學習及實作。美國亞馬遜電子書,可看到第二章的第8個機率分配(Weibull distribution) ↩
-
Richard M. Vogel (2020): The geometric mean?, Communications in Statistics-Theory and Methods, DOI:10.1080/03610926.2020.1743313 ↩
-
Limbrunner, J.F.; Vogel, R.M.; Brown, L.C. 2000. Estimation of Harmonic Mean of a Lognormal Variable ↩
-
美國亞馬遜電子書 - Demythologize Durbin-Watson test statistic 用於確定正確的臨界值 ↩
-
唯一適合度檢定做為測定機率分配的軟體:建模軟體(限windows作業系統為繁體中文版;免安裝,下載後解壓縮,將「建模軟體」資料夾拖曳至C槽) ↩
-
Hsiao C-W, Chan Y-C, Lee M-Y, Lu H-P. Heteroscedasticity and Precise Estimation Model Approach for Complex Financial Time-Series Data: An Example of Taiwan Stock Index Futures before and during COVID-19. Mathematics. 2021; 9(21):2719. ↩