區間估計和假設檢定是統計學中的第二和第三步。第一步是找到統計量,做點估計。 區間估計和假設檢定計算都不難,Excel或統計套裝軟體都能跑出來。但是軟體內有沒有問題呢?哪裡會出問題? 區間估計和假設檢定倒底哪裡難?從根源去找就可以知道難點在哪?問題在哪?
1. 觀念介紹
網上有很多文章都在教學區間估計(Confidence interval)的統計觀念。他們都認同計算區間估計門檻高,並且還要先知道數據來自何種分配,才能運用各種分配對應的誤差範圍計算公式。
然而,區間估計的計算公式只有一個
\[Pr(|Z|<Z_{\alpha / 2})= \alpha\]上式中的$Z$是指標準化的意思,也就是Z score,非指Z分配。只有當確定可以趨近常態分配後才能使用Z分配。$(1 - \alpha)\times 100$% 為信賴水準,$0<\alpha<1$。
你可以標準化任何隨機變數或隨機樣本的數學組合。常見的隨機樣本的數學組合有樣本平均數(包含樣本比例)、樣本變異數、樣本標準差、樣本偏態係數、樣本峰態係數、樣本之和等。過去從國中到大學所學過的數學函數或衡量指標公式都能成為隨機樣本的公式或函數計算。
統計學教科書通常只教樣本平均(包含樣本比例)和樣本變異數的區間估計和假設檢定,原因在於統計學的統計量配合極限理論可以讓樣本平均趨近常態分配,兩樣本變異數之比為F分配進行區間估計和檢定。這是對應常態分配的兩個參數做的設定。
2. 極限理論
這些隨機變數或隨機樣本的數學組合會服從特定分配,我們稱為抽樣分配(Sampling distribution)。不過,難就難在這些轉換後隨機樣本的抽樣分配太難找了,於是,從數學家棣美弗開始,他們發現原來可以增加樣本個數達到趨近常態分配的特性,後稱為中央極限定理(Central limit theorem)1。
你以為就只有中央極限定理嗎?當然不止。這類的極限理論(limit theorem)包含分配趨近(convergence in distribution)2、機率趨近(convergence in probability)3、幾乎確定趨近(almost surely convergence)4,其中,
- 中央極限定理是基於存在期望值和變異數的分配,趨近累積機率分配,此為分配趨近。
- 弱大數法則來自機率趨近
- 強大數法則來自幾乎確定趨近
三種趨近方法以確定趨近最強,次之為機率趨近,最後為分配趨近。
只要談到趨近就不脫離樣本個數($n$)。在實際應用上樣本個數需要多少才能產生趨近效果是很多人都想知道,但理論卻沒有說明的地方。這導致很多公說公有理,婆說婆有理的情況。
2.1. 你以為你知道軟體後面使用正確的理論?
我們用簡單的例子來說明。網路上常用的區間估計計算器5就是個錯誤例子。這是來自某書籍提供的線上計算區間估計程式。我設定的是偏態的母體比例,$p=0.9$,這時候肯定要用中央極限定理,並且樣本數要足夠大才可能讓偏態的母體比例抽樣分配變成常態分配。
當我設定樣本數11筆,臨界值為Z分配的1.96。

當我設定樣本數30筆,臨界值為Z分配的1.96。
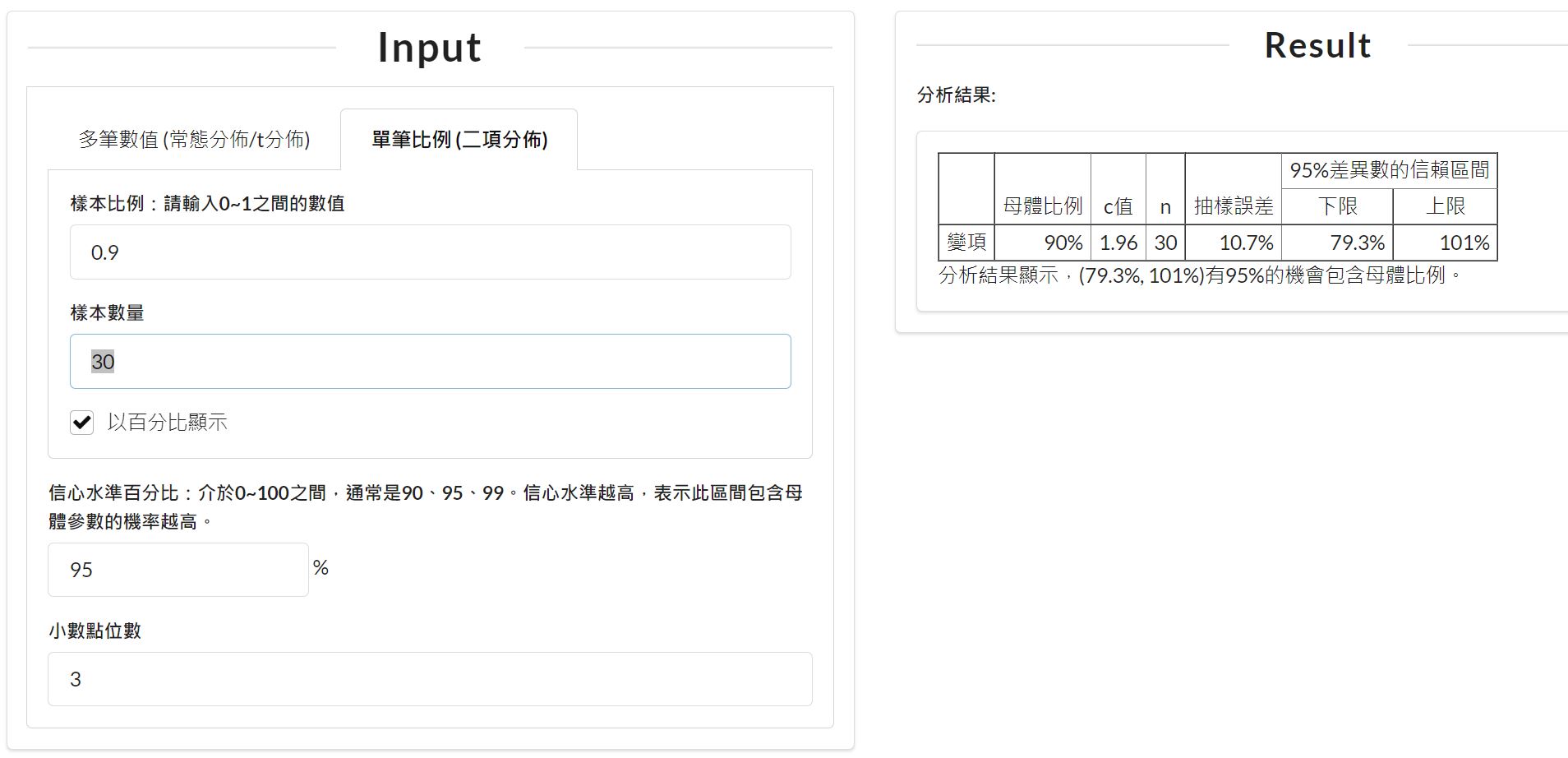

這三張截圖可以看出無論樣本數多少,臨界值都是使用Z分配的1.96,甚至出現不符合中央極限定理要求樣本數超過30的條件,此外,樣本比例為0.9應為偏態,若要適用中央極限定理,所需樣本數也要非常多,至少超過1500個樣本6。
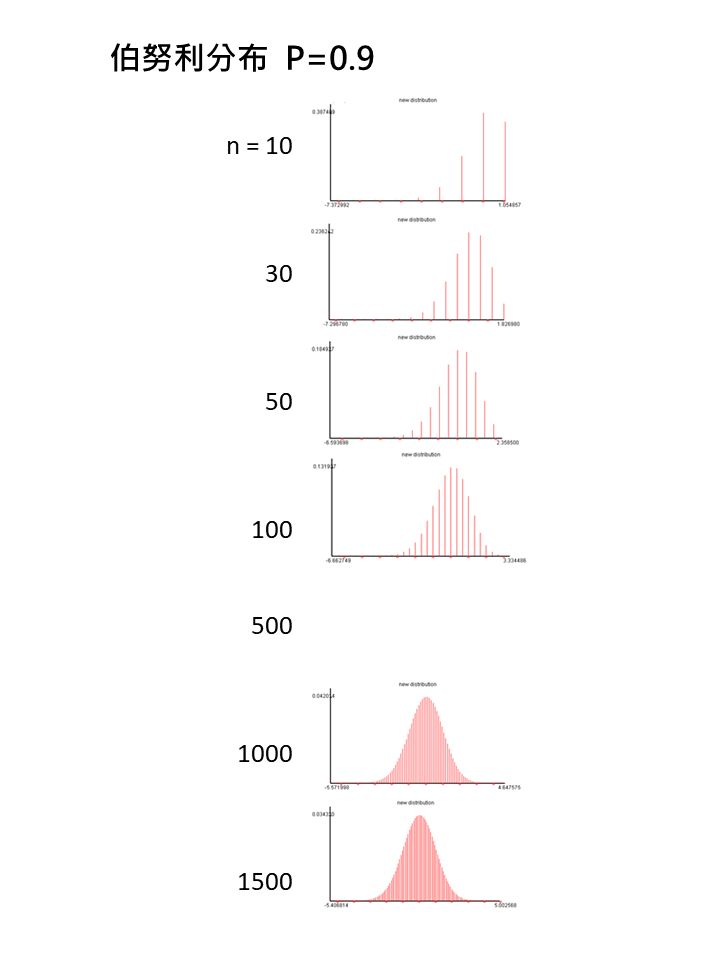
沒有使用極限理論驗證過統計量的抽樣分配何時趨近常態分配,那就只是理論的中央極限定理。
3. 統計學的區間估計或假設檢定公式沒有混亂之說
為什麼有些人會覺得統計學在做區間估計或假設檢定時,公式很混亂呢?因為他們都是背公式,套公式,而沒有真正了解統計學這些公式的來源。
回到第一節我提到的區間估計概念: $Pr( \lvert Z \rvert < Z_{\alpha /2})= \alpha$ 。翻譯成中文為
「標準化的統計量($Z$)」落於$-Z_{\alpha / 2}$和$Z_{\alpha / 2}$之間的可能性為 $(1 - \alpha) \times 100$%。
「標準化的統計量($Z$)」可以為
\[Z=\frac{\overline{X}-E(\overline{X})}{\sigma(\overline{X})}\]其中,$\sigma(\overline{X})$是$n$的函數。常見的的函數形式為$\sqrt{n}^{-1}$。
3.1. $n$個隨機樣本服從常態分配
平均數為$\mu$且標準差為$\sigma$的常態分配,$E(\overline{X})=\mu$ 且 $Var(\overline{X})=\sigma^{2} /n$。所以,「標準化的統計量($Z$)」為
\[\begin{split} Z & = \frac{\overline{X}-E(\overline{X})}{\sigma(\overline{X})} \\ &=\frac{\overline{X}-\mu}{\sigma/\sqrt{n}} \end{split}\]3.2. $n$個隨機樣本服從伯努利分配
如果隨機樣本$X_{1}, X_{2}, \cdots , X_{n}$獨立地服從伯努利分配,$B(1,p)$,其樣本平均為$\sum_{i=1}^{n} X_{i} / n$,也是統計量。
因為伯努利相加為二項式分配,所以$n$個隨機樣本相加服從二項式分配,$B(n,p)$。透過期望值特性和變異數特性,可以計算得到
\[\begin{split} E(\overline{X}) &= p \\ Var(\overline{X}) &= p(1-p) / n \end{split}\]「標準化的統計量($Z$)」為
\[\begin{split} Z & = \frac{\overline{X}-E(\overline{X})}{\sigma(\overline{X})} \\ &=\frac{\hat{p}-p}{\sqrt{p(1-p) / n}} \end{split}\]3.2.1. 舉例比對
讓我使用來自雪梨大學的一個母體比例區間估計計算器7和使用來自機率分配模擬器的一個母體比例估計得到臨界值後計算的區間估計。
設定有100個隨機樣本且母體比例為0.9,此時的抽樣分配仍非常態分配。紫色背景圖是來自雪梨大學的一個母體比例區間估計,介於0.8256~0.9448。

來自機率分配模擬器的臨界值如下圖所示,並可計算得到區間估計的信賴區間為
\[[0.9-1.997373 \times \sqrt{(0.9 \times 0.1)/100}=0.840079, 0.9+1.668280 \times \sqrt{(0.9 \times 0.1)/100}=0.950048]\]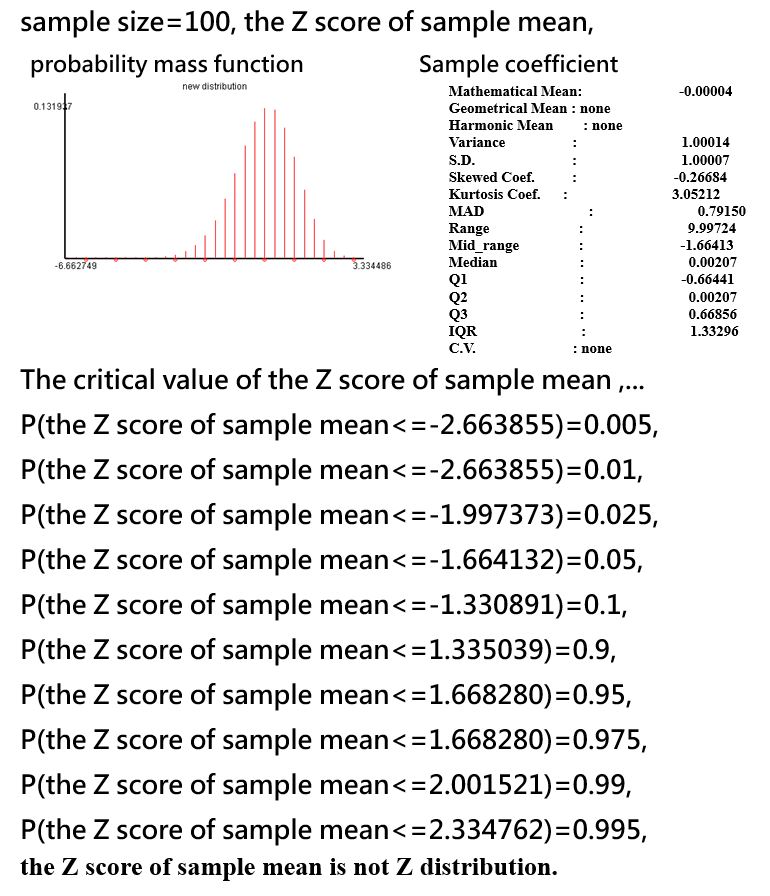
3.2.2. 比對表
我將上面的兩種方法進行表格的比對如下。
| 來自 | 雪梨大學區間估計計算器 | 機率分配模擬器 |
|---|---|---|
| 方法 | 套用Wilson score無連續性公式 | 使用機率分配模擬器則經過1億次的「每次100個隨機樣本」得到一個母體比例標準化後的抽樣分配,再由抽樣分配找出臨界值,代入一個母體比例的信賴區間公式 |
| 臨界值 | 來自標準常態分配 | 來自機率分配模擬器 |
| 95%信賴區間下界 | 0.8256 | 0.840079 |
| 95%信賴區間上界 | 0.9448 | 0.950048 |
| 上界-下界 | 0.1192 | 0.10997 |
觀察上表可發現,
- 100個樣本不足以讓p=0.9的一個母體比例抽樣分配趨近常態分配,而是有左偏的抽樣分配。95%信賴區間內的上下界不會是對稱型的位置。
- 機率分配模擬器得到的區間範圍往右,這不是因為一個母體比例的標準差造成的誤差,而是臨界值的準確性讓區間範圍變小。
4. 小結
統計學的區間估計和假設檢定不困難,公式也不混亂。我們只要抓穩這兩個統計學知識點的根本:
- 他們都是為了找母體參數
- 一個用樣本逼出母體參數範圍,一個測定假設的母體參數值
- 使用的統計量都要標準化
了解公式一開始的觀念,就只是將不同的統計量套入標準化和觀念進行計算即可。真正的難點在於沒有人做以下3點:
- 找出隨機樣本數學組合的抽樣分配
- 即使找出抽樣分配,多少樣本才能趨近常態分配
- 少於趨近常態分配的樣本數下,如何得到抽樣分配
這導致了至少4點問題:
- 要考慮間斷轉連續問題。統計學的一個母體比例區間估計和假設檢定出現了很多的公式。除了多少樣本才能趨近常態分配外,另一個問題就是間斷轉連續問題。
- 忽視估計和檢定的目的是找母體參數。統計學只重視樣本平均和樣本變異數的區間估計和假設檢定。但未必能用於每個機率分配的參數的區間估計和假設檢定,例如,柯西分配的參數是中位數,做樣本平均的區間估計和假設檢定一點意義都沒有。
- 只重視樣本平均和樣本變異數。統計學無法為其他樣本係數做區間估計和假設檢定。例如,樣本變異數其實也有抽樣分配,因為無法找到抽樣分配,就直接一階動差(期望值)用卡方檢定了。事實上,樣本變異數的變異數是四階動差8。是的,只要樣本數夠大,中央極限定理又可以使用了,但問題回到難點2和3。至於其他敘述統計的係數之抽樣分配,幾乎無法想像怎麼求得。
- 誰知$n\rightarrow \infty$是多少樣本。實務上中央極限定理最少要多少樣本數眾說紛紜。最後都是自我認定或約定成俗。這種模糊化造成的誤差都被視而不見。
有沒有解決方法呢?前面有提到一些,之後在開其他篇談談吧。