1. 常態分配基本介紹
1.1. 名稱
常態分配(Normal distribution) = 高斯分配(Guassian distribution) = 鐘型分配(Bell distribution)
2.2. 符號
$X \sim N \left(\mu, \sigma^{2} \right)$
1.3. 使用時機
這是一個適用於解釋誤差的分配。所謂的誤差是指一特定隨機變數($X$)和其目標($\mu$)的差距,以符號表示為,$\varepsilon = X - E(X) = X - \mu, E(\varepsilon^{2})=\sigma^{2}$。
- $\mu$ 為位置參數
- $\sigma$ 為形狀參數
1.4. 機率密度函數
令一隨機變數為 $X$,滿足 $E(X)=\mu$ 和 $Var(X)=\sigma^{2}$。 令新的隨機變數為 $X$ 標準化, $Z=\frac{X-\mu}{\sigma}$。
機率密度函數為
\[f_X(x)=\frac{1}{\sqrt{2 \: \pi} \: \sigma} \times e^{\frac{-1}{2} \: Z^{2}}, - \infty < x < \infty \tag{1}\]累積機率密度函數為
\[F_X(x)=\int_{- \infty}^{\infty}\frac{1}{\sqrt{2 \: \pi} \: \sigma} \times e^{\frac{-1}{2} \: Z^{2}} \: dx =1 \tag{2}\]式(2)可改寫為
\[\int_{- \infty}^{\infty} e^{\frac{-1}{2} \: Z^{2}} \: dx = \sqrt{2 \: \pi} \: \sigma \tag{3}\]1.5. 動差母函數
\[\begin{align} M_{X}(t) &=E(e^{t \, X}) \\ &=\int_{- \infty}^{\infty}\frac{e^{t \, x}}{\sqrt{2 \: \pi} \: \sigma} \times e^{\frac{-1}{2} \: Z^{2}} \: dx \\ &=\int_{- \infty}^{\infty}\frac{1}{\sqrt{2 \: \pi} \: \sigma} \times e^{\frac{-1}{2 \sigma^{2}} \: (x-\mu)^{2}} \times e^{tx} \: dx \\ &=e^{t \: \mu + \frac{t^{2} \, \sigma^{2}}{2}} \tag{4} \end{align}\]- 期望值: $E(X) =\mu$
- 變異數: $Var(X) = E(X^{2})- \left[E(X)^{2} \right] =\sigma^{2}$
- 偏態係數: $\gamma_{1}=E \left[Z^{3} \right] = 0$
- 峰態係數: $\gamma_{1}=E \left[Z^{4} \right] = 3$
1.6. 圖形特徵
- 母體的算術平均數 = $\mu = E(X)$ = 中位數 = 眾數
- 反曲點: $\mu - \sigma$ 和 $\mu + \sigma$
2. 如何模擬常態分配
使用蒙地卡羅模擬方法模擬常態分配的數值。當數值來自 $N(\mu, \sigma)$,可生成 $X= \mu + \sigma \times Z$,其中, $Z$ 為常態分配變數標準化。
設定蒙地卡羅模擬的亂數產生於均勻分配, $F_{X} (x)=U \sim U(0,1)$。
令兩個來自均勻分配的隨機變數為 $U_{1}和U_{2}$,根據Box-Muller Transform 公式1為
\[Z_{1}=\sqrt{-2 \, ln(U_{1})} \times cos \left(2 \, \pi \, U_{2} \right)\]和
\[Z_{2}=\sqrt{-2 \, ln(U_{1})} \times sin \left(2 \, \pi \, U_{2} \right)\]$Z_{1}$ 和 $Z_{2}$ 為獨立標準常態分配, $N(0,1)$。
2.1. 使用Excel模擬常態分配
想要模擬出常態分配,你以為前面的兩條數學式就足夠嗎?不!我根據YouTube2的方法,使用Excel亂數生成常態分配出一組數據。此時,還需要第三個均勻分配,$U_{3}$ 做為控制器。因此可得到公式(5)。
\[IF(U_{3}<=0.5,mu +sqrt(-2*ln(U1))*cos(pi()*U2*2)*sigma, \\ mu+sqrt(-2*ln(U1))*sin(pi()*U2*2)*sigma) \tag{5}\]從Excel上可生成來自常態分配的隨機樣本
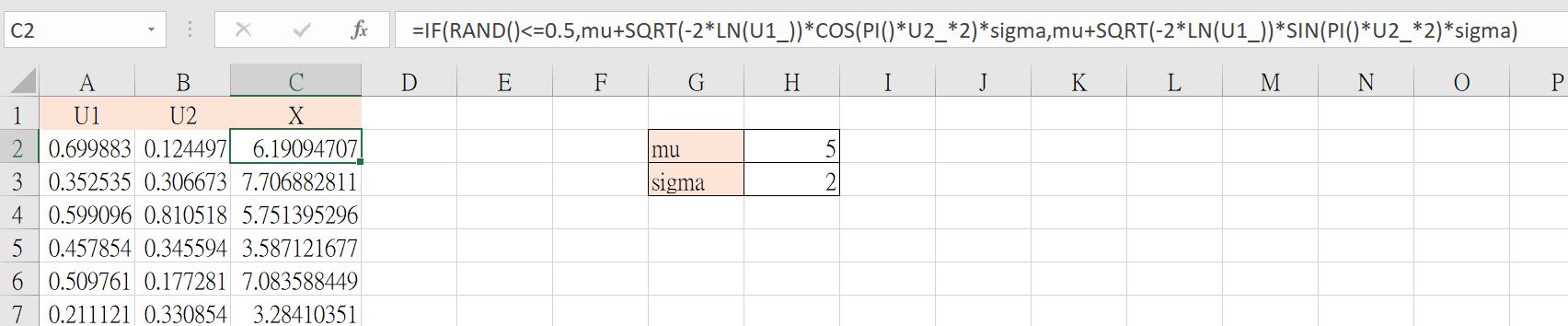
一個試算表使用 ctrl+shift+↓,可以選取到如下圖這般多的列數:1,048,576。扣除第一列為標題列,我們可以生成1,048,575個隨機樣本。
有需要我使用的Excel檔案,請在聯繫我。我會附檔回信給你,或是在臉書粉絲專頁對應這篇文章的貼文下留言,我會私訊給你。
2.2. 比對指令法和亂數法的常態分配差異
為什麼亂數方式得到的數據比直接用指令還要優異?讓我歸納一下兩者的差異:
| 差異點 | 機率分配模擬器 | 指令法 |
|---|---|---|
| 隨機性 | 數字仍存在隨機性 | 數字已經不存在隨機性 |
| 數字來源 | 亂數轉換生成 | 數學公式計算得到 |
| 可否繼續數字轉換 | 可以 | 不行 |
| 第一次使用得到的 | 先得到數據,再由 數據得到次數分配表 |
直接是次數分配表 |
透過亂數的機率分配模擬器產生的數值,建立相對次數分配表和圖(如下圖),可以發現,同樣為常態分配,但因來自亂數隨機,1百萬的數據仍會讓常態分配圖有細微的波動。

指令法得到的數值是由非亂數產生的數字,所以從E欄可看出當A欄數字逐漸增加時,機率值以穩定的數學式計算得到,使得數字非常穩定。換言之,指令法當中已不存在數字隨機性。如若我們將這些指令用在大數據和人工智慧模型中,去比對數據,原該有的隨機性,只會發生在數據中,而不是既有的機率分配中。
亂數的機率分配模擬器生成的常態分配還可以經由轉換得到第3節要講到的其他分配。如果你使用指令,就只能做到這樣。常態就是常態、t分配就是t分配,F分配就是F分配。
參考資料
-
維基百科:Box-Muller transform ↩
-
YouTube中機率分配模擬器影片https://youtu.be/lpR0rN3GKcg?t=144。如果需要知道機率分配模擬器,可在Google搜尋「probability distribution simulator youtube」 ↩