- 前言
之前我已經發布了兩篇有關如何使用Excel製作直方圖《如何在Excel中畫直方圖 Part I》和《如何在Excel中畫直方圖 Part II》。不過,這兩篇文章所用的Excel在二個隨機變數且每個隨機變數皆分類200組時,需要一定的等待時間讓Excel運算。另外一篇《二維常態分配介紹》也是有相同的問題。
之所以講到這樣簡單的直方圖作法皆是機器學習、深度學習、深度AI等使用統計方法都會採用直方圖。但他們已經習慣英國制定的直方圖規範,認為組數不超過20組,或最多設定25組就達到極限。你認為真是如此嗎?
還記得學習間斷和連續的數學概念時,連續可以轉換成間斷,例如使用高斯函數只取小數點前的數字。但間斷怎麼轉成連續呢?這可傷腦筋了!電腦的運算方法更是遭遇到這樣的問題,這也讓大數據或人工智慧總是圍繞著「分類」和「計數」。這些個間斷概念遇到連續型的數字時,電腦運算將連續型數字轉為間斷處理,可我們有沒有辦法讓「間斷趨近連續」呢?這在數學的推論中可以做到,電腦上能嗎?
在我們的研究中發現如果數據量能夠超過1億筆,並且將數據集內的每組數據分類成270組,各組數據繪製的直方圖就能趨近連續,而聯合機率則使用$200 \times 200$個所有可能數字組合,形成聯合機率分配 (參考圖1)。
那麼我們倒底有沒有辦法繪製出漂亮的兩隨機變數的聯合機率分布圖呢?在博客來網路書店販售的《統計學不能做為大數據分析的工具-原因與補正》一書後面附贈軟體就可幫助我們繪製出二隨機變數的270組的聯合機率(圖1)和一個隨機變數的邊際機率(圖2)。
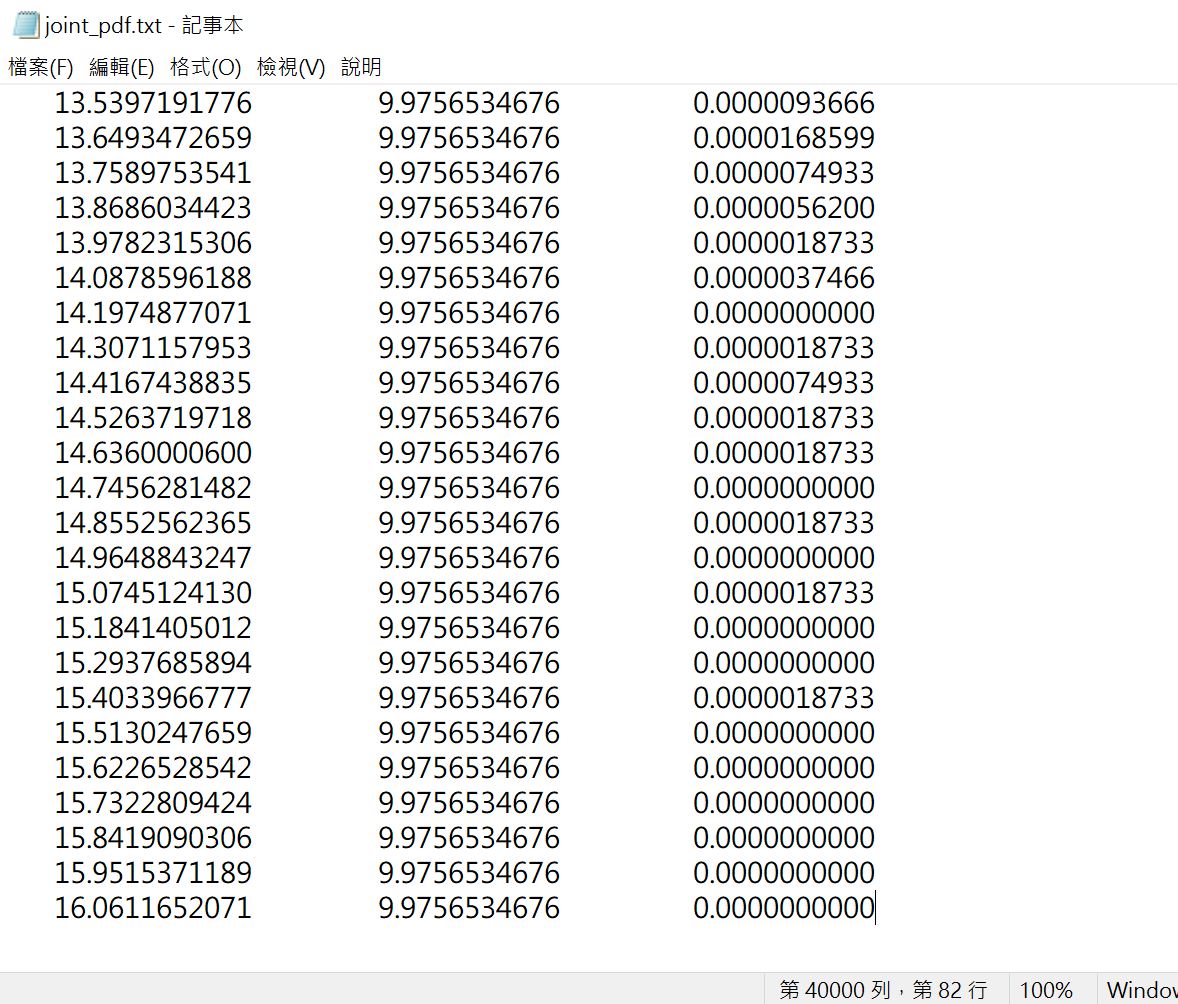 圖1
圖1
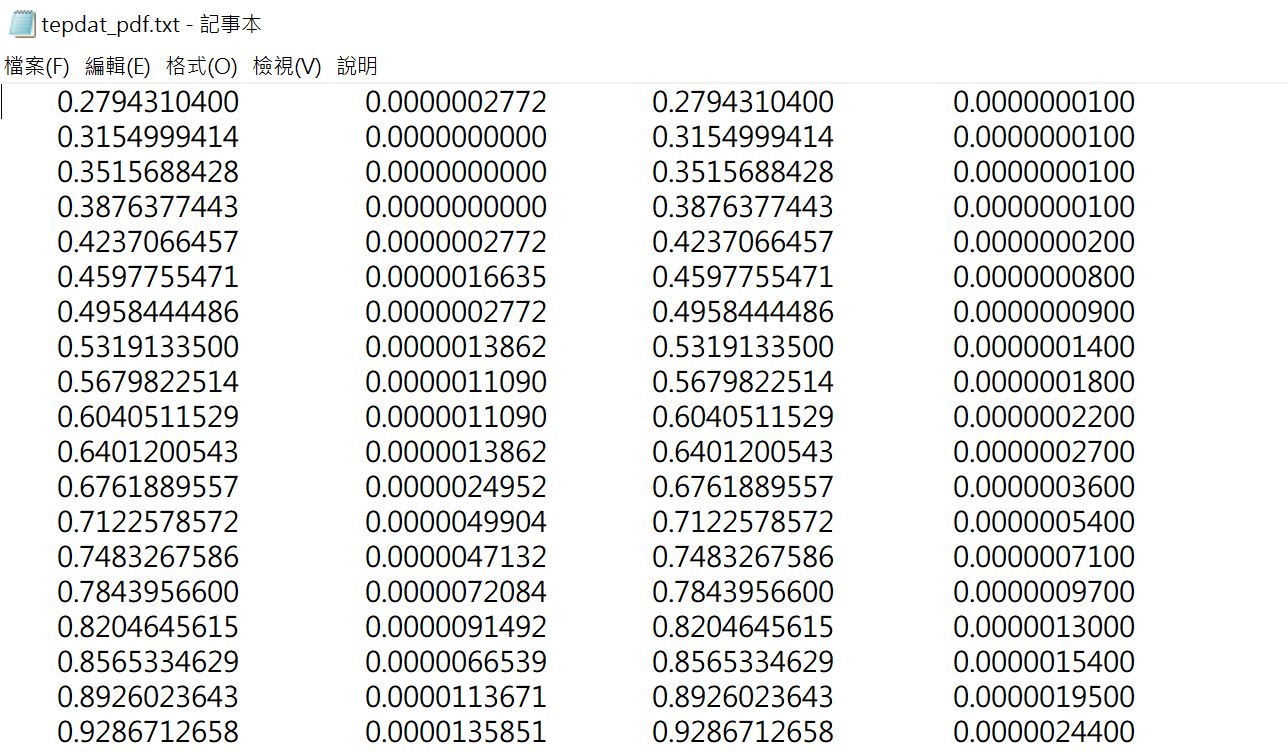 圖2
圖2
我將說明如何使用軟體幫助我們繪製出圖形,同時還能得到繪製使用的數據及1億筆的數據結果。
2. 上操作過程
其實用影片展示這類的操作過程是最佳的成果,我過去教授大數據分析時已經錄製好以《統計學不能做為大數據分析的工具-原因與補正》為教科書的課程內容。想要付費學習這類數據分析方法的朋友們可以私訊我。
當我們開啟畫面時,入眼的就是功能選單。有關軟體功能介紹可到 YouTube 觀看。
 圖3
圖3
在【selecting】右邊鍵入【1】代表我們要使用功能1。然後點擊【ending】上方圓點後就會跳到下一個畫面。
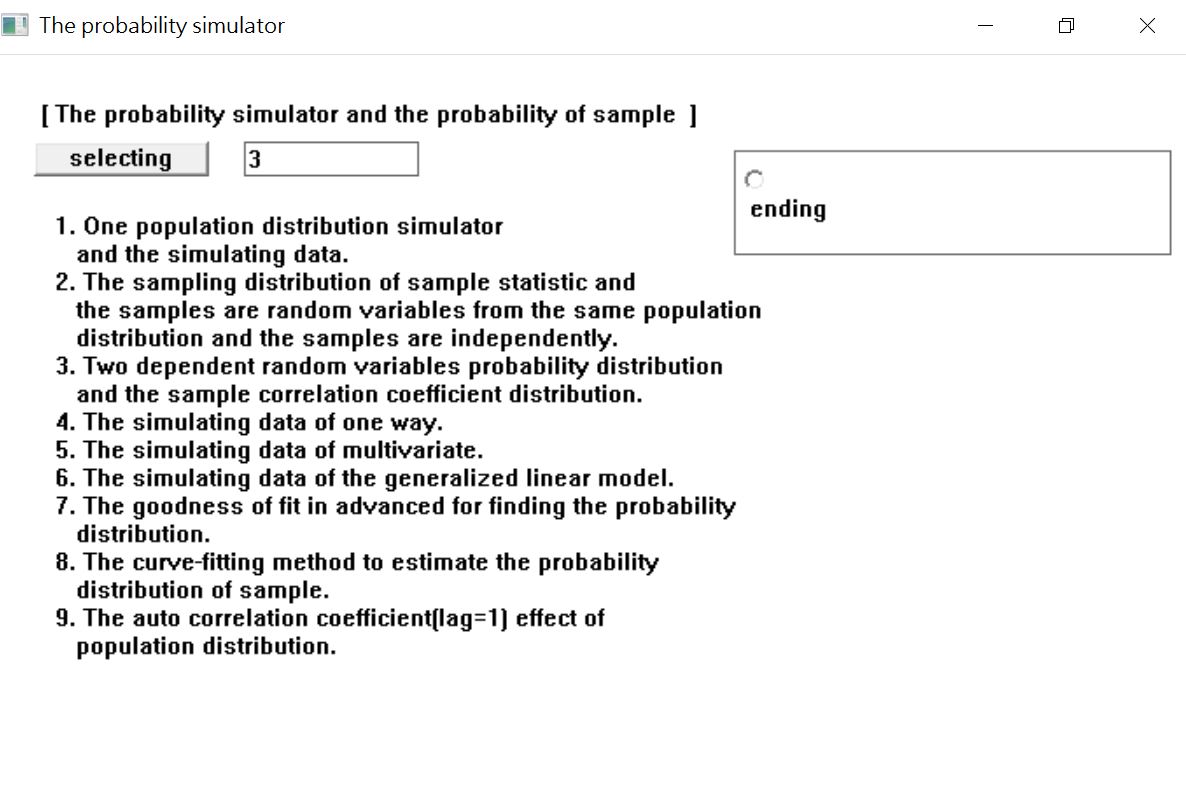 圖4
圖4
在圖4,如果想生成一個隨機變數,可選擇圖4畫面選單中的【1】。而我想要生成兩個獨立隨機變數的數據,所以選【3】。
 圖5
圖5
圖5出現後,就是設定我們數據要服從的機率分配。書中有45種分配可以選。書籍的附錄中顯示每個分配的代號。此處我設定第一個分配是常態分配,平均數為5,標準差為2,並且我想要產生1億筆的成對樣本。
 圖6
圖6
圖6開始設定第二個隨機變數的分配。這裡可以設定獨立或相關。根據畫面下方的說明,如果你將b1或b2或b3設定為非零數字,就會讓第一個隨機變數影響第二個隨機變數,兩變數產生了相關。
如畫面所示,我將H()設定為1,表示第二個隨機變數和第一個隨機變數有直線相關。這就是傳統簡單迴歸模型的條件期望值。
 圖7
圖7
圖7為軟體提示,確認你設定是否正確。你可以看到我設定的是:
- 第一個隨機變數:常態分配
- 第二個隨機變數:柏拉圖1分配
- 兩個隨機變數獨立
 圖8
圖8
軟體來到圖8的畫面,開始模擬生成數據了。
 圖9
圖9
完成模擬後,軟體會如圖9的提示視窗畫面,詢問要不要看圖。此時你有兩個選擇【是】或【否】。選擇【是】,軟體就會畫圖。
注意:軟體依賴繪圖的程式為JAVA。電腦要先安裝JAVA才能顯示圖形。不然畫面就此停住不會再繼續下去。一般來說Windows 10系統建議安裝JAVA 10。
選擇【否】則不會畫圖直接開始抽樣,產生1億筆的成對樣本。
我接下來選擇【是】。
 圖10
圖10
圖10畫面開始為繪圖做運算,先得將數據進行排序。
 圖11
圖11
完成後,出現圖11的提示視窗,即將要開始繪圖了。
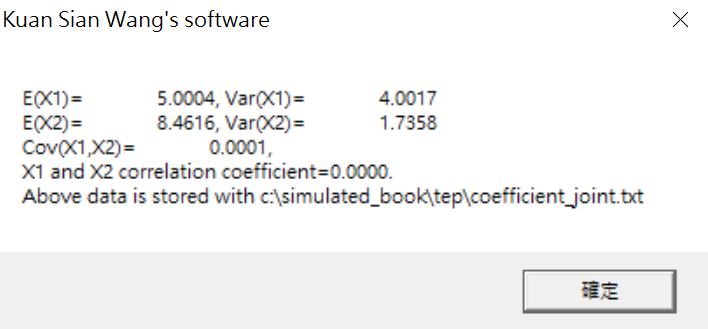 圖12
圖12
繪圖前,還是要算一下兩個隨機變數的關係。這個軟體的優勢在於每個步驟的運算結果都會保留下來,所以你可以在還沒有按【確定】或【是】之前將temp資料夾的檔案進行保留。
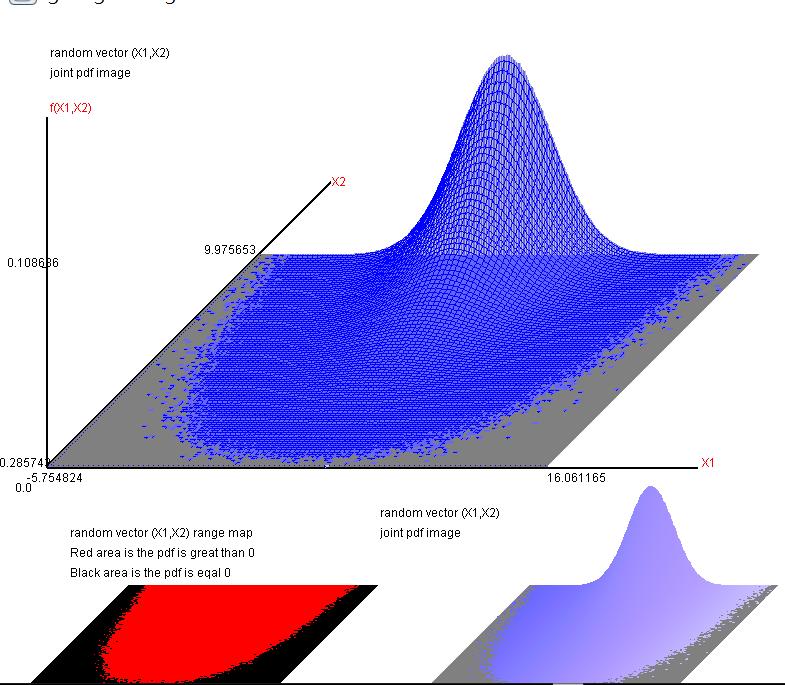 圖13
圖13
圖13就是JAVA繪製的聯合分配圖,同時底面積圖(紅色區域)可以讓學習者知道兩獨立隨機變數,一個服從常態分配,一個服從柏拉圖1分配,形成這樣的底面積代表兩者的關係。如果你非要使用簡單迴歸去估計,其估計結果可能不盡理想。
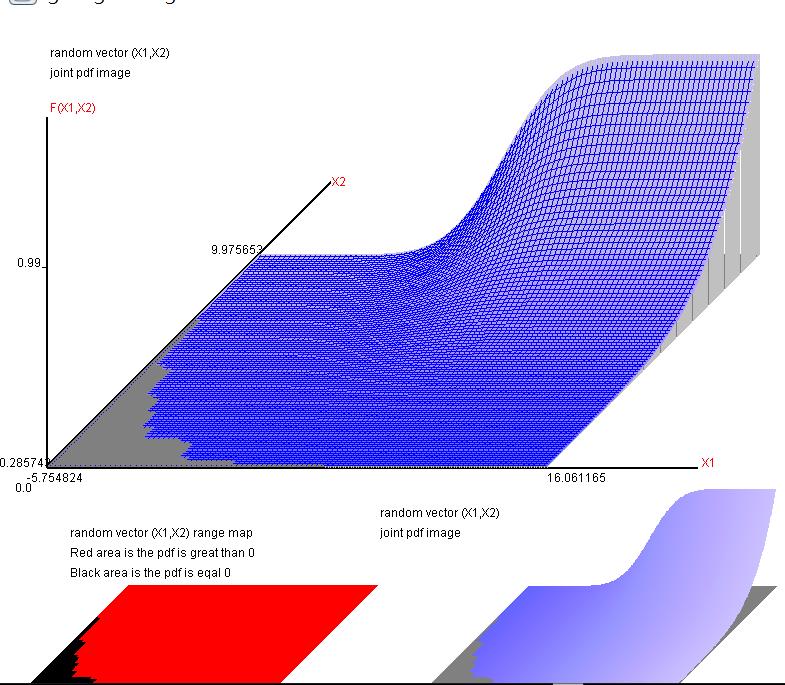 圖14
圖14
圖14顯示累積聯合機率分配圖。
圖13和圖14都是由$200 \times 200$ 種可能得到的結果。
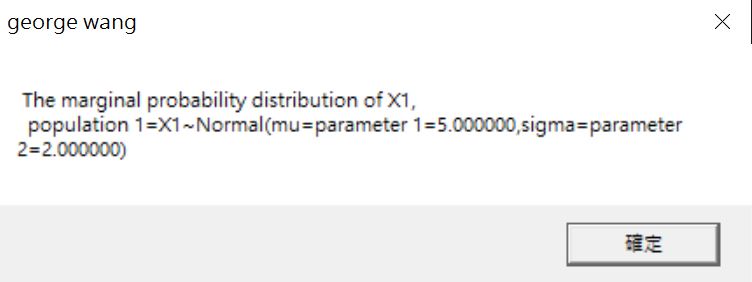 圖15
圖15
聯合分配圖繪製完成後,軟體接著開始繪製一個隨機變數的邊際機率分配圖。
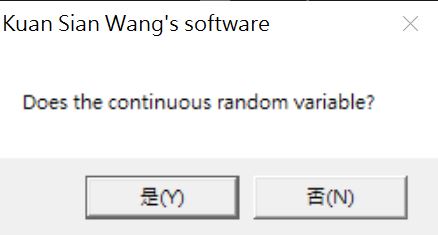 圖16
圖16
對於邊際機率分配圖的繪製上,軟體會詢問是否為連續型的隨機變數。
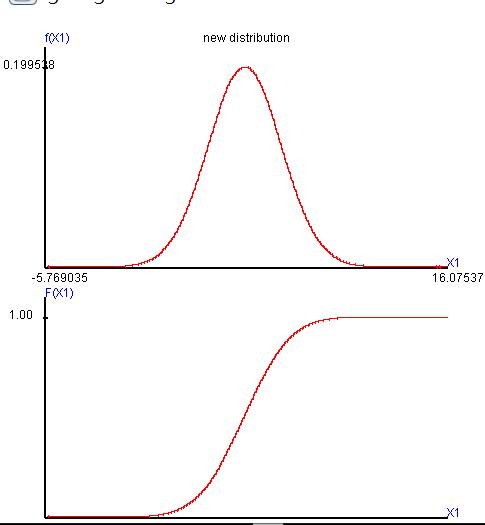 圖17
圖17
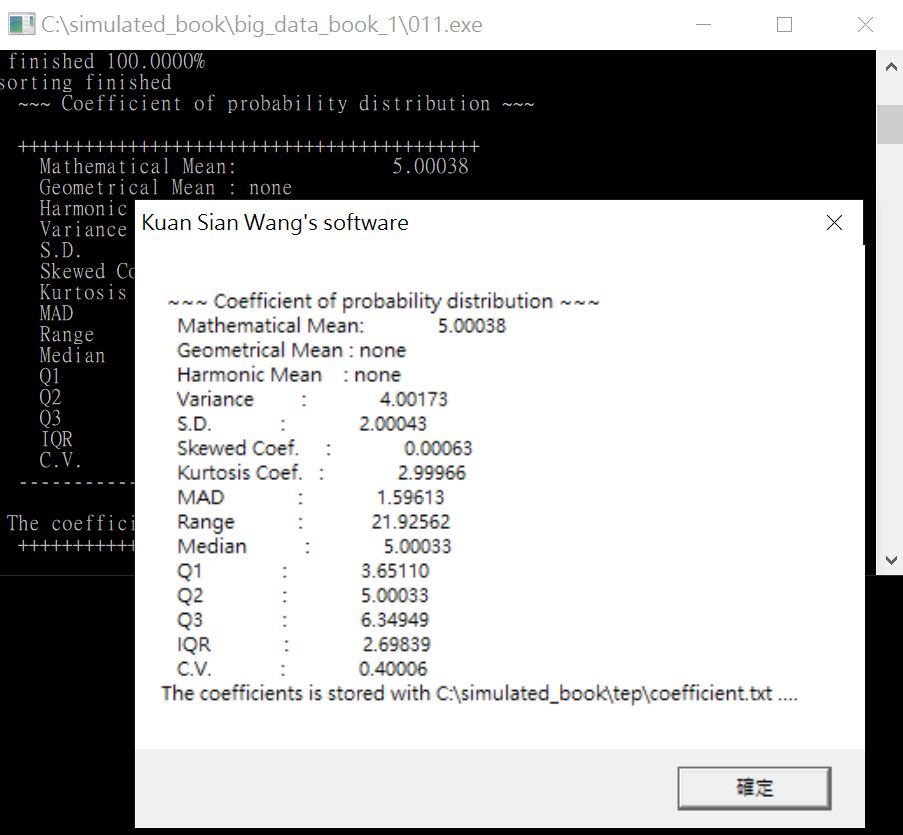 圖18
圖18
第一個隨機變數在設定時就已經知道是「常態分配」,因此我們就能夠由圖17和18確認。可以看係數表的算術平均數、標準差、偏態係數和峰態係數。
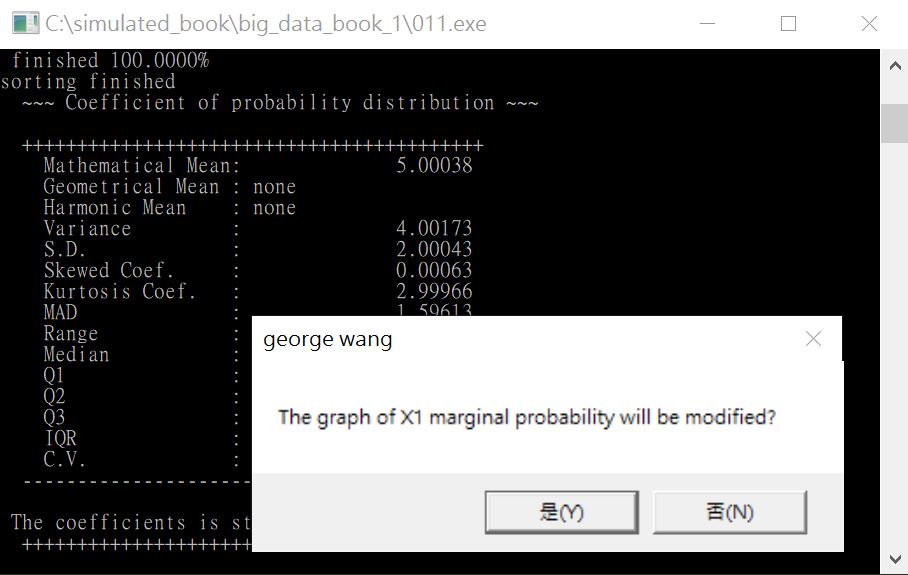 圖19
圖19
接著,軟體會有一個特別的功能,讓你可以優化分配。如果你選圖19畫面的【是】,就進入優化分配的設定。如果選【否】,進入第二個隨機變數的邊際機率分配圖繪製。
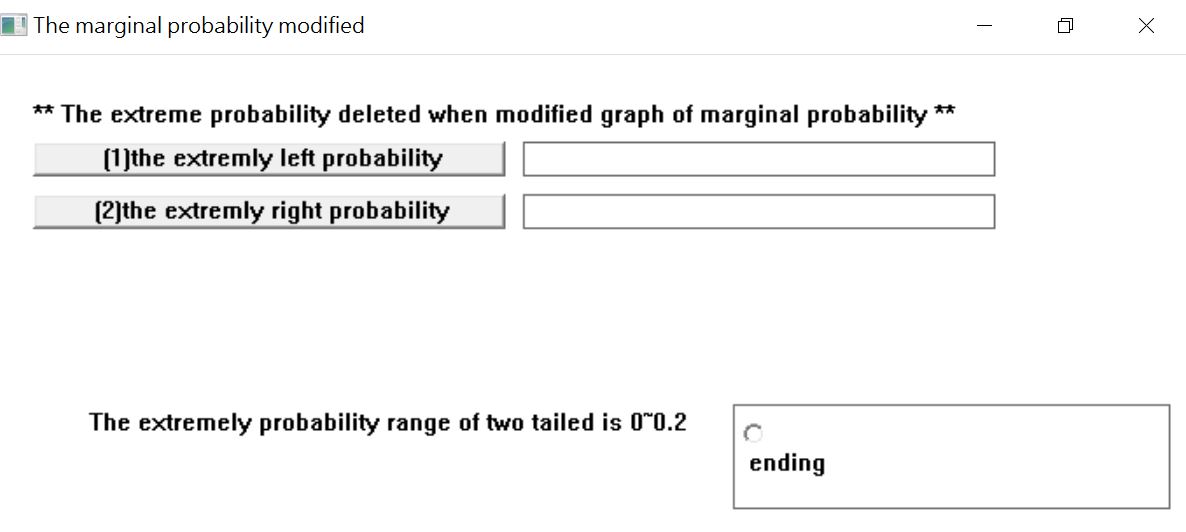 圖20
圖20
選擇【是】,進入優化分配的設定畫面如圖20所示。你可以剔除左右兩邊的極端值。數值設定可從0 ~ 0.2,也就是左邊或右邊極端值佔比0%至20%。
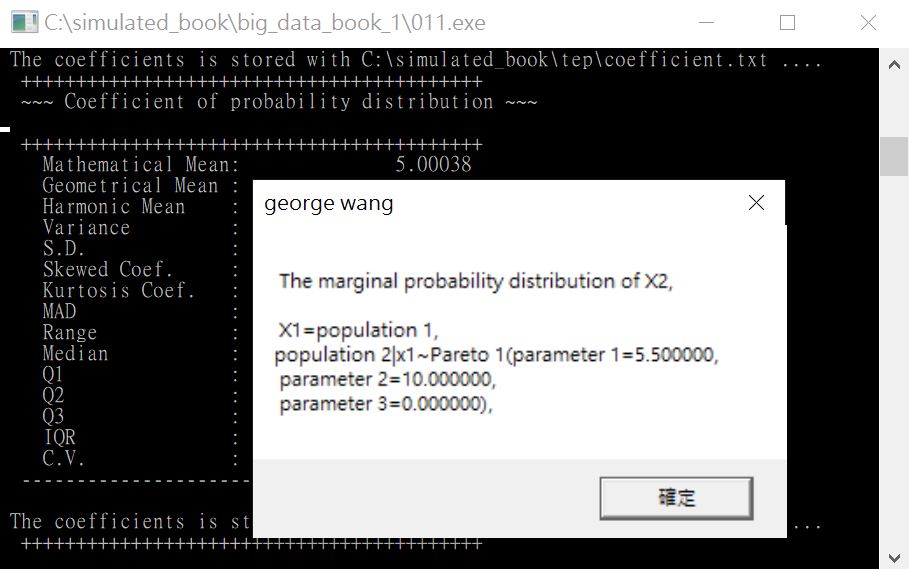 圖21
圖21
如果不優化,就進入第二個隨機變數分配繪製。此時出現圖21的提示視窗。
 圖22
圖22
軟體一樣會詢問第二個隨機變數是連續型變數還是間斷型。
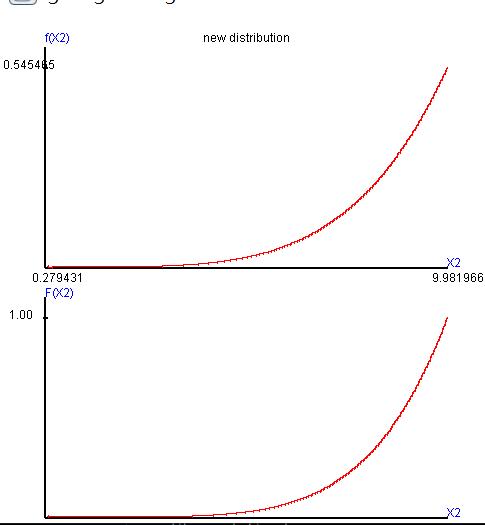 圖23
圖23
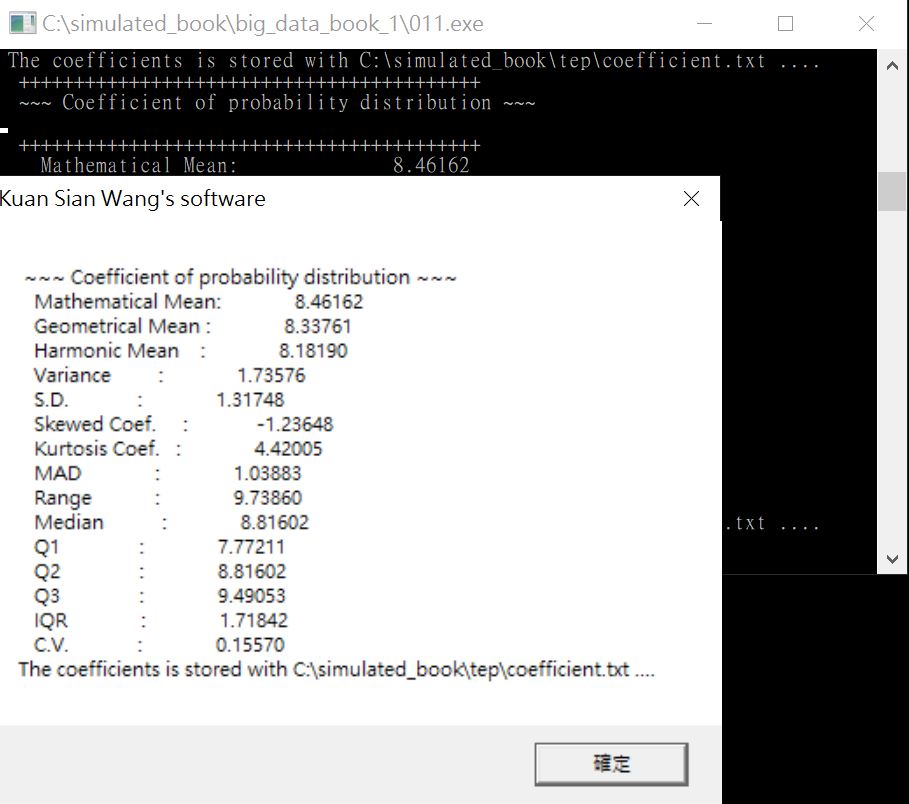 圖24
圖24
接著軟體就會繪製出圖形(圖23)和係數表(圖24)。
 圖25
圖25
同樣地,軟體對第二個隨機變數也會詢問是否要優化分配。選擇是,進入圖20畫面。選擇否,進入圖26畫面。
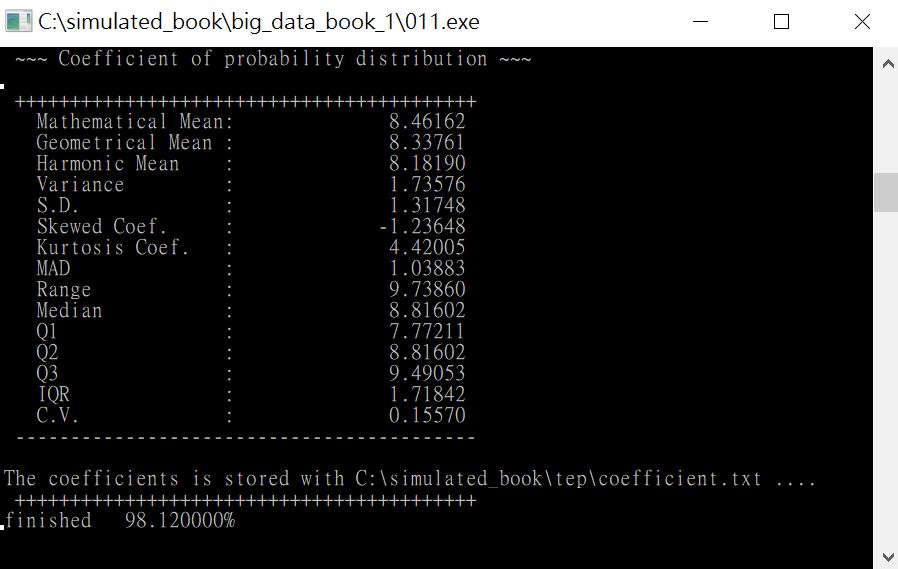 圖26
圖26
圖26畫面為軟體開始生成數據。
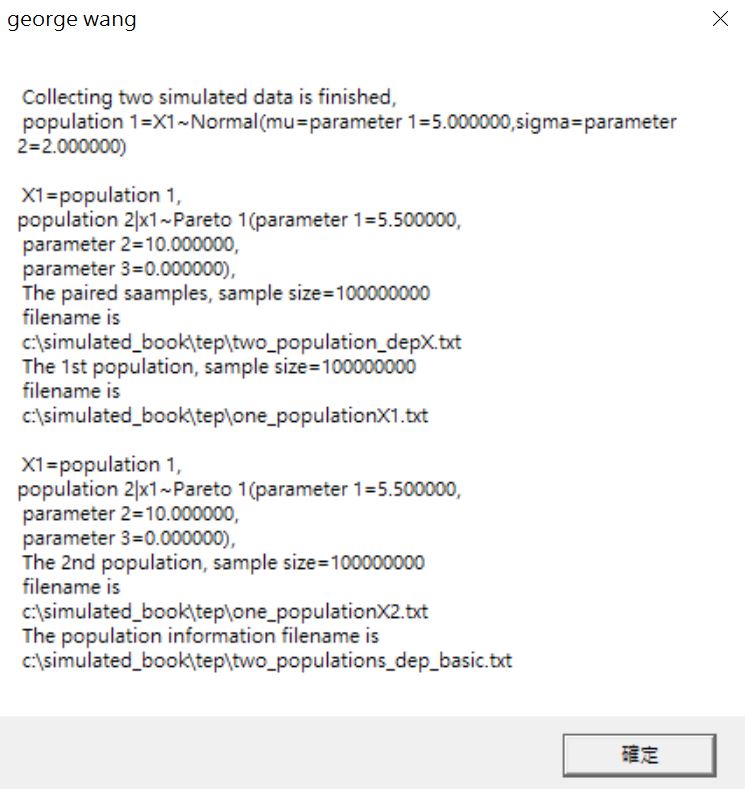 圖27
圖27
數據生成完畢,跳出圖27畫面,顯示兩隨機變數的設定,以及生成的數據量有多少,並且存放在哪。
3. 小結
這是一套C語言開發的大數據分析軟體,第一個功能為機率分配模擬器(圖3),模擬數值的功能從1到6(圖4),可以應對各種模型對應的數據模擬。很少人懂得數值模擬的功用。這可謂是「數據模型的沙盒」。我很喜歡「沙盒」一詞,這來自於遊戲開發的模擬。同樣地數據模型也該有模擬情境的沙盒,讓我們知道數據的可能變化,模型自然也會不同。而非現階段常見的「線性迴歸」發展出來的「嶺迴歸」或LASSO等。
有的大數據或人工智慧模型已經使用到「非線性迴歸」模型,但觀察專家學者們認為的「非線性迴歸」模型形式就那數種而已!很想問問有沒有檢測標準?有沒有能夠確認數據真的就是那種非線性函數形式嗎?
在這篇文章中,圖6下方的說明可以讓使用者或想學習數據分析的朋友們了解,你需要的數學觀念是國高中的函數觀念就能夠幫助你理解非線性迴歸的函數形式,甚至你可以使用這樣的功能,將模擬數據用繪圖方式呈現圖13的底面積,再搭配統計學迴歸分析的設定的那個線性方程式就是條件期望值。如此連結觀念,你更能知道迴歸分析在做什麼,以及它不足之處在哪。
想想看,明明可以讓兩個隨機變數產生函數關聯,函數形式只有線性、指數、對數、平方、三次方這樣而已嗎?讓我舉個例子更能展現非線性函數的威力。
在期貨數據的分析中,通常有個非常重要的影響因子:期貨契約到期特性。你可以用虛擬變數或其他方法代表這個契約到期性質,那為什麼明明跟時間因素有關,卻不能用時間變數呢?
是的,專家學者們很有意思的地方就在這邊。他們都認為時間變數是個不是成因的因子,只是因為取得數據的特性而造成需要加入時間變數,例如時間序數據。但迴歸分析的基礎假設中對數據的要求就是具有「累加性」,時間序就是一種「累加性」的數字,另一個常見的名稱叫做等差級數。
各位朋友們,有沒有很熟悉的感覺?
因此,時間變數的$1,\,2,\,3, \cdots,\,T$,加上非線性的轉換就能夠顯示期契約到期特性,看到那個波的間隔1。
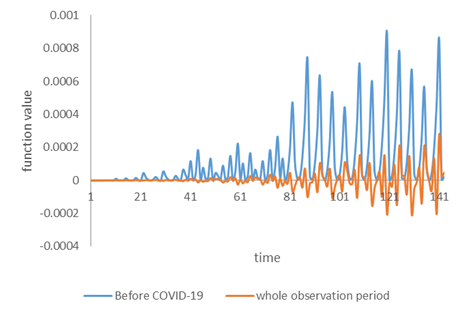
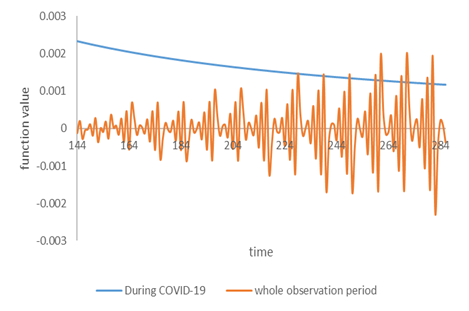
雖然這對某些人,或可說那些現在在數據分析、計量經濟學領域頂尖的20%人而言不是件好事[笑],我仍是要說隨著科技的進步,數據分析方法也會隨之進步與改善。我們保持一顆開放的心欣賞著這些數據模型之美,也是一件樂事。
參考資料
-
Does COVID-19 Change the Relationship among Taiwan Stock Index Futures, MSCI Morgan Taiwan Index, and Taiwan Stock Price Index? https://economics.expertjournals.com/23597704-903/ ↩