1. 前言
我們手邊的數據有很多種,可能是原始數據,或者已經變成「報酬率」形式,在財金數據中特別常見。而這種經過報酬率公式計算得到的數字,代表數據已經做了函數轉換,成為新的數據型態。所以這樣的數據若無法轉換回原始數據狀態,那麼可以稱為新的數據。
我還記得很多人都會問我一個很有趣的問題:論文都用報酬率分析財金數據,你為什麼要用原始數據估模型。這一點意義都沒有。第二個問題是使用報酬率也可以還原回原始數據,這不會有影響的。下面就讓我一一做解答,如此大家就能知道如果要做數據分析或大數據分析時需要注意的點。
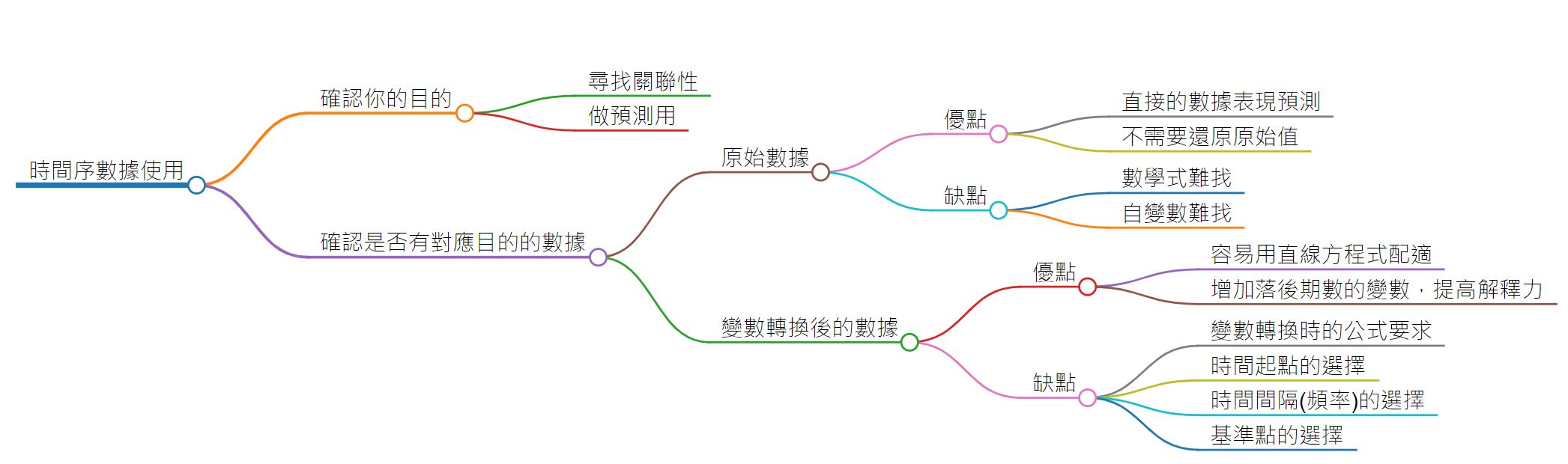
2. 先確定你的研究目的
每次的研究目不同需要的數據不同。例如,當我們想要比較五檔股票時,該怎麼比較才好?直接拿股價去比,有的高,有的低,所以不好比較。此時若能夠有可以讓比較時的基準點一致,同時還能去單位,不受單位影響,後者對跨國不同幣別的股價比對特別有幫助,這樣的數據就能確切迎合分析目的。報酬率也確實可以做到比較基準點一致和去單位,達到做跨國或跨產業的股票比對。
不過,我們就只做這樣的研究目的嗎?比對和資產配置等主流研究論文就需要上述的報酬率協助完成論文研究,而有一群人則喜歡研究數據的建模和預測。例如過去有段時間,灰色系統應用在財金數據分析非常熱門,後續則是類神經網路法在研究財金數據的預測性。不過前二者的方法並無法顯示出數據估算後的數學模型形式,甚至這二法的的數據分布假設都還是在特定分配上。就我個人嘗試過多個股價指數個股的股價,選擇不同的研究期間,以及切割不同的時間點有可能造成數據的機率模型差異。
多數我們研究這樣財金數據的目的是為了知道未來股價指數或股價會發生什麼事情,也就是「預測」。這種「預測」是針對數據的研究期間之外的時間點進行估計。在傳統的迴歸分析中也有預測值和預測區間的介紹,請注意到這都是基於線性迴歸假設下才成立。
所以,我們得先確定你的研究目的後,去選擇數據類型或決定是否要做變數變換,產生新的數據。再由新的數據執行研究。
3. 報酬率適合做預測嗎?
想回答這個問題就得先對報酬率的計算公式來個解說。讓我列出報酬率的公式如式(1)
\[R_{t}=\frac{Y_{t}-Y_{t-1}}{Y_{t-1}} \times 100 \% \tag{1}\]這公式重點除了變數$Y$之外,就是$t$了。$t$代表時間點。那來自時間點的影響是什麼呢?
-
要有起始時間點
。你可以選一年的開始,也可以一年的任一日,甚至選擇從某年開始都是影響研究報酬率這類數據特性帶來不同的結果。
-
頻率
。 什麼叫做頻率呢?報酬率可以是「日報酬率」、「週報酬率」、「月報酬率」、「季報酬率」、「年報酬率」等。這些名詞前面的「日」、「週」、「月」、「季」、「年」就是數據的頻率。
- 選擇哪種頻率的數據由個人決定。有時還可以計算「三年報酬率」或「五年報酬率」。
- 可能發生的問題:你選擇不同頻率的報酬率就代表除了那兩點的價格外,中間發生的價格都不管了。 在這點上,有些人可能使用平均價格的方式。
- 提醒:當你看到的研究使用這樣的數據時,需要考慮到這樣的數據意義在哪,畢竟數據已經被扭曲了,未必能夠還原到原始數據。如果一定要連結回原始數據的走勢、變化或趨勢,就需要確定扭曲後的數據代表性真的足夠嗎的問題。
-
計算的基期:「-1」
。 雖然我在式(1)使用「-1」的符號代表前一期。那什麼叫做「前一期」?
- 根據時間序排序。 例如,2021年8月的前一期就是2021年7月。這是從時間序的排序的先後次序確認前一期。
- 與去年同期。 礙於季節調整影響,在多數的數據庫中,前一期可能是「與去年同期」。例如,2021年8月的前一期就是2020年8月。
報酬率最大影響就是來自你選擇的起始點、數據頻率,還要選擇前一期的定義,這些都是研究者自己主觀認定選擇的。有的人認為要用年報酬率,有的人認為要用月報酬率,至於為什麼他們這樣認為也是根據研究所需要而使用。而預測則要看預測的未來時間點在哪。
例如我想預測的是明天,所以使用「日」頻率的報酬率或原始數據會是比較合適的。如果我想預測的是一年後,那我使用「年」頻率的數據會比較好。
4. 報酬率可以做預測原始數據嗎?
那你可能會開始思考:報酬率不能變成做「預測」使用嗎?其實可以的!如果我們跟隨專家學者最常使用的線性迴歸研究方法得到式(1),
\[\frac{Y_{t}-Y_{t-1}}{Y_{t-1}}= \hat{\beta_{0}} + \hat{\beta_{1}} \, R_{X,t} \tag{1}\]改寫式(1),得到
\[Y_{t}= Y_{t-1} \left(1+\hat{\beta_{0}} + \hat{\beta_{1}} \, R_{X,t} \right) \\ =Y_{t-1} \left(1+ \hat{R}_{Y,t} \right) \tag{2}\]式(2)的分母全部都知道,前一期的Y值也知道。所以很明顯可以由報酬率反推回t期的Y值。此結果即使是多個自變數也可以成立。
看起來還不錯!那如果報酬率的估計式變成這樣呢?
\[R_{Y,t}=\beta_{0}+\beta_{1} \, R_{X1,t}^{3} + \beta_{2} \, R_{X2,t} + \beta_{3} \, ln(R_{X3,t}) \tag{3}\]式(3)當中的$R$代表報酬率。是的,我們可以視為等式右邊都是已知,並且$Y$的前一期也是已知,自然得到式(2),只是括號內的估計式比較複雜點。
5. 選擇原始數據還是報酬率做預測?
那你可能會想:不使用股價指數或股價,將之轉換成前面提到的報酬率是不是就可以解決選擇不同研究期間和切割不同時間點造成機率模型不穩定的可能這裡,我們還是得回到標題,確定自己的研究目的為何。
研究過程中如果可以直接使用原始數據得到誤差最小且精準的數學模型,進而得到誤差最小的預測值,為什麼不使用原始數據,還使用一次轉換或多次轉換後的數據(例如報酬率)呢?我們的研究目的很清楚地是在實務上使用,直接得到明天的預測值,那麼我要建立的數據模型自然就會是使用原始數據,並由此原始數據得到最佳的數學模型後,進行預測。
至於使用報酬率做預測可以嗎?當然也是可以的,這仍有保證前提是:誤差最小且精準的數學模型。然後再由估計得到的明日報酬率,根據式(2)轉換回原始數據的預測值。你可以兩種數據都做一次,再確定要選哪種數據做預測使用。
這裡我留下一個伏筆 - 誤差最小且精準的數學模型。其實在我前面的一些文章中也有提到過,例如數據分析流程的心智圖或是我與合著作者們發表在 Mathematics 期刊的論文。或許過去的文獻已經提到過使用報酬率在迴歸估計後可以得到很好的預測力,有興趣的朋友可以去比對一下。而我提到這「誤差最小且精準的數學模型」已經在2020年2月至4月的新冠病毒爆發與蔓延之初,各大分析師無法預測美股如何時就已經成功驗證此研究方法的可行性。
因需要每日都要追蹤與預測的做法,以及還有很多因素影響著股市變化,當時的追蹤股價指數的過程中驗證了數據模型如何反饋出政府政策和市場力量的抗衡。這些結果十分地多,想寫成論文不是件容易的事情。因此,都放在網路上免費給人下載參考。
6. 小結
沒有任何的觀點或理論可以壓抑住我們在數據分析時最想要的實務目的:找到數據的模型和做預測!即使專家學者們加入各種的自變數了解財金數據的關聯,可最終目的還是落實於實務上,未來趨勢和未來預測。
不過,為什麼那麼少人使用原始數據做預測呢?我歸納了三點原因:
- 原始數據的數學建模又要精準,又要誤差最小實在太難了,與其耗費時間在上面,不如另闢途徑,建立關聯模型,仍維持在線性迴歸之上,讓方法不變,卻能提高預測力。所以別用原始數據,從此走上另一條數據類型的分析領域。
- 直接用原始數據實在難以找到與之對應的自變數,通常就用時間變數,做為學術研究來說,太貧乏了。學術研究範疇一下就做完,那還搞什麼,對吧?所以關聯分析可以讓研究的廣度增加,深度增加,各種經驗產生的變數關聯都可以被拿來驗證。而關聯性模型建立好後,我們就可以從關聯去推估,去預測。看起來很棒,成功的可能性也很高。而歷史的學術軌跡也告訴我們確實如此。時至今日的大數據和人工智能應用在財金上也是使用關聯性模型。
- 原始數據耗時費力,當時候的電腦運算沒有現在來得好,不如換研究方法,例如類神經網路,決策數分析等。總有可以做得到,並成功的可能,畢竟科學就是實驗出來的。
報酬率適合預測或建模嗎?報酬率的使用通常來自理論,多名諾貝爾經濟學獎得主也因此而得獎,於是跟隨者眾,終成大宗!但反思自己的目的,以及未來主流的大數據和人工智慧接軌情況,前述的第二點仍是主流。沒關係!那數據類型呢?還用報酬率嗎?你們覺得報酬率有什麼問題嗎?我提出了報酬率的計算公式中需要注意的3大點。當我們改變那3點計算影響因子,你們認為報酬率數字會改變嗎?改變後還會讓你得到穩定的結果嗎?有沒有人試驗過報酬率實際不受納3點的影響,還是會受其影響呢?
我自己對報酬率的使用抱持著存疑的態度,研究歸研究,實務上,部落格中的預測股價指數的紀錄文章中,我還是直接使用原始數據找出精準且誤差最小的數學模型後,做預測。
我記錄下這些,讓後面想做這方面研究的人能夠少走一些路,而非盲目地跟隨宗師級的研究方法,學術作假還是有發生的可能,例如醫學的某心臟研究權威作假實驗數據,後續跟隨並同樣做出支持該權威的學術成果的專家學者們真是情何以堪。我也不認為我的研究方法一定正確,只是到目前為止,我自己嘗試過都是可行的,自然也希望有興趣的朋友們可以一起使用,在數據分析領域中找出數據特徵、規律,為問題可解決,為決策者可有決策依據。