1. 前言
美國在2022年6月10日公布5月的消費者通膨率於近12個月內達到8.6%,是40年來最高點(美國勞工部資料)。直接上美國聯準會(FED)的網站了解此這項消費者通貨膨脹率的計算基礎為「所有城市消費者的消費者價格指數:美國城市平均所有項」,並且計算的方式為「與去年同期相比」的比率值。
對此,我將使用不同於美國勞工部使用的未經季節調整的數據,改以經季節調整數據計算YOY值,並以此當作每月之通貨膨脹率進行機率分配模擬器的應用分析案例。
2. 美國每月通貨膨脹率的基本描述
2.1. 直方圖
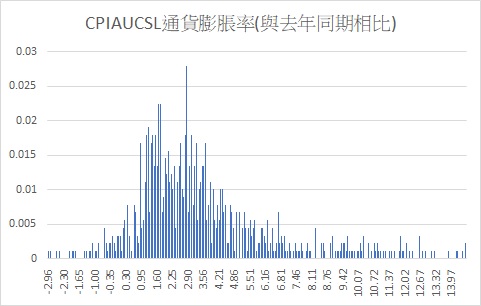
根據機率分配模擬器的Excel方法將所有的CPIAUCSL計算得到之YOY值,繪製出270組的直方圖,觀察下圖可發現,從1947年開始的美國每月通貨膨脹率數據多數集中在0~7區間,同時也會有發生高通膨的可能性。
2.2. 敘述統計表
| 係數 | 數值 |
|---|---|
| sample Mean | 3.49626 |
| Geometrical Mean | none |
| Harmonic Mean | none |
| sample variance | 8.44520 |
| sample S.D. | 2.90606 |
| Skewed Coef. | 1.33874 |
| Kurtosis Coef. | 5.02982 |
| MAD | 2.12162 |
| Range | 17.58040 |
| MIN | -2.98813 |
| MAX | 14.59228 |
| C.V. | 0.83119 |
2.3. 尋找機率模型
我將使用「改良式適合度檢定」和「曲線配適的隨機變數法」測定CPIAUCSL數據的機率模型。如果改良式適合度檢定可以測定出數據的機率模型,就不再使用第二種方法。
2.3.1. 改良式適合度檢定
由於我不知道CPIAUCSL數據為何種機率分配,所以就選擇完整的45種分配檢定。
45種分配檢定後,可得到最佳的分配為
H0: population distribution ~ Gumbel,type I(a = 0.520000, b = 3.011026), H1: against H0
pearson goodness of fit
| class | [ 1 ] | [ 2 ] | [ 3 ] | [ 4 ] | [ 5 ] | [ 6 ] | [ 7 ] | [ 8 ] | [ 9 ] | [ 10 ] |
|---|---|---|---|---|---|---|---|---|---|---|
| lower limit | 0.51431 | 1.20426 | 1.76218 | 2.28703 | 2.82420 | 3.41158 | 4.10302 | 5.00484 | 6.44872 | |
| upper limit | 0.51431 | 1.20426 | 1.76218 | 2.28703 | 2.82420 | 3.41158 | 4.10302 | 5.00484 | 6.44872 | |
| observed no | 64.00000 | 76.00000 | 127.00000 | 83.00000 | 91.00000 | 103.00000 | 87.00000 | 73.00000 | 72.00000 | 117.00000 |
| probability | 0.10000 | 0.10000 | 0.10000 | 0.10000 | 0.10000 | 0.10000 | 0.10000 | 0.10000 | 0.10000 | 0.10000 |
| expected no | 89.30000 | 89.30000 | 89.30000 | 89.30000 | 89.30000 | 89.30000 | 89.30000 | 89.30000 | 89.30000 | 89.30000 |
| chi square | 7.16786 | 1.98085 | 15.91590 | 0.44446 | 0.03236 | 2.10179 | 0.05924 | 2.97525 | 3.35151 | 8.59227 |
degree of freedom=7
chi square test=42.375140
p value=0.000000
由於P value 小於0.05,顯著地拒絕虛無假設,所以我們無法說數據服從Gumbel,type I分配,不過,這是從45種分配經過適合度檢定後得到最小卡方統計量的分配,代表美國每月通貨膨脹率仍存在此分配特徵。我根據此分配進行機率分配模擬器的模擬,得到下圖。
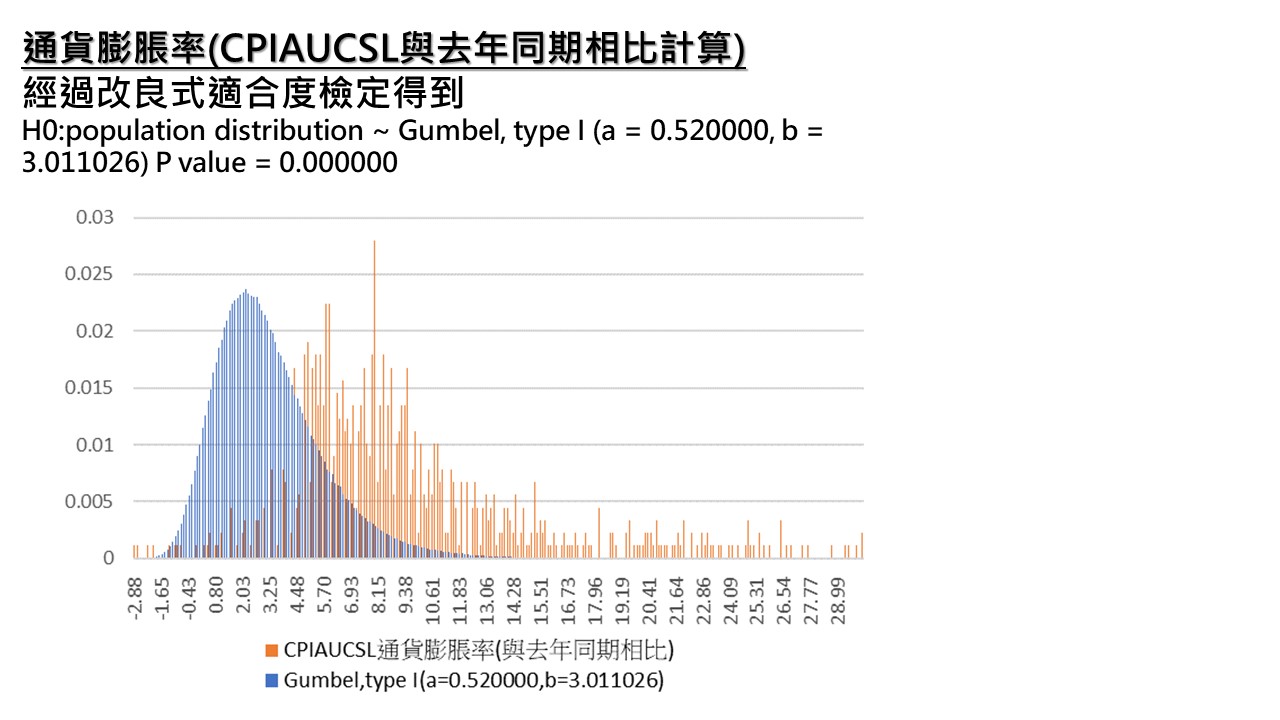
觀察此圖可發現美國每月通貨膨脹率確實有幾分Gumbel,type I分配特徵。但仍需要進行第二種的測定機率模型方法。
2.3.2. 曲線配適的隨機變數法
觀察數據的直方圖,決定切割為6部分,並且每部分估算最高30次方。每個部份的估算數學式如下。
第一部分:$0.001120 < F(x) \leq 0.165733$
The random variable value estimated line ——
\[X= 192.88975393772125000000+ \\ 482.51013374328613000000 \times log(F(x))^1+\\ 516.04724454879761000000 \times log(F(x))^2+\\ 305.57915663719177000000 \times log(F(x))^3+\\ 109.57115811109543000000 \times log(F(x))^4+\\ 24.41532200574874900000 \times log(F(x))^5+\\ 3.30896980687975880000 \times log(F(x))^6+\\ 0.24992307554930449000 \times log(F(x))^7+\\ 0.00807052385061979290 \times log(F(x))^8+\]Error = 0.146592043798855880
MAX = 0.141631660950682250,
coefficient of determination = 0.998588170146954780
第二部分:$0.166853 < F(x) \leq 0.332587$
The random variable value estimated line ——
\[X= -293.32458829879761000000+\\ 7479.969512939453100000000000000000 \times F(x)^1+\\ -78374.542236328125000000000000000000 \times F(x)^2+\\ 433438.727539062500000000000000000000 \times F(x)^3+\\ -1333594.490234375000000000000000000000 \times F(x)^4+\\ 2164450.140625000000000000000000000000 \times F(x)^5+\\ -1447877.062500000000000000000000000000 \times F(x)^6+\]Error=0.010702420783148791 MAX=0.027723386168057251, coefficient of determination=0.998045248679701460
第三部分:$0.333707 < F(x) \leq 0.499440$
The random variable value estimated line ——
\[X= 2.85741416798555290000+\\ 3.82546988502144810000 \times tan((F(x)-0.5)*\pi)^1+\\ 128.77674627304077000000 \times tan((F(x)-0.5)*\pi)^2+\\ 2325.69432640075680000000 \times tan((F(x)-0.5)*\pi)^3+\\ 20482.01361083984400000000 \times tan((F(x)-0.5)*\pi)^4+\\ 100564.63464355469000000000 \times tan((F(x)-0.5)*\pi)^5+\\ 288965.47265625000000000000 \times tan((F(x)-0.5)*\pi)^6+\\ 483004.45263671875000000000 \times tan((F(x)-0.5)*\pi)^7+\\ 435075.01757812500000000000 \times tan((F(x)-0.5)*\pi)^8+\\ 163308.76367187500000000000 \times tan((F(x)-0.5)*\pi)^9+\]Error = 0.010601918353702691
MAX = 0.022936677771675296,
coefficient of determination = 0.998897554600459810
第四部份:$0.500560 < F(x) \leq 0.666293$
The random variable value estimated line ——
\[X= 2.88886196957901120000+\\ -6.030633330345153800000000000000*log(F(x)/(1-F(x)))^1+ \\ 227.293088912963870000000000000000*log(F(x)/(1-F(x)))^2+ \\ -3313.868652343750000000000000000000*log(F(x)/(1-F(x)))^3+ \\ 26782.372802734375000000000000000000*log(F(x)/(1-F(x)))^4+ \\ -130189.990234375000000000000000000000*log(F(x)/(1-F(x)))^5+ \\ 395362.636718750000000000000000000000*log(F(x)/(1-F(x)))^6+ \\ -754632.992187500000000000000000000000*log(F(x)/(1-F(x)))^7+ \\ 879147.859375000000000000000000000000*log(F(x)/(1-F(x)))^8+ \\ -571090.742187500000000000000000000000*log(F(x)/(1-F(x)))^9+ \\ 158550.117187500000000000000000000000*log(F(x)/(1-F(x)))^10+\]Error = 0.009479544896608603
MAX = 0.022147767012969499,
coefficient of determination = 0.998975064075794510
第五部分:$0.667413 < F(x) \leq 0.833147$
The random variable value estimated line ——
\[X= 208.61537551879883000000+\\ 5584.70962524414060000000*(F(x)-1)^1+\\ 63297.06152343750000000000*(F(x)-1)^2+\\ 376269.65820312500000000000*(F(x)-1)^3+\\ 1233769.57031250000000000000*(F(x)-1)^4+\\ 2116615.36718750000000000000*(F(x)-1)^5+\\ 1485876.35937500000000000000*(F(x)-1)^6+\]Error = 0.059148709190885093
MAX = 0.055542576265771082,
coefficient of determination = 0.998780058468952010
第六部分:$0.834267 < F(x) \leq 0.997760$
The random variable value estimated line ——
\[X= 15.60729745682328900000+\\ 408.75996494293213000000*(F(x)-1)^1+\\ 20770.55682373046900000000*(F(x)-1)^2+\\ 622792.94531250000000000000*(F(x)-1)^3+\\ 7574088.00000000000000000000*(F(x)-1)^4+\\ -54189580.00000000000000000000*(F(x)-1)^5+\\ -2879210976.00000000000000000000*(F(x)-1)^6+\\ -38058847232.00000000000000000000*(F(x)-1)^7+\\ -250082772992.00000000000000000000*(F(x)-1)^8+\\ -836079431680.00000000000000000000*(F(x)-1)^9+\\ -1134545690624.00000000000000000000*(F(x)-1)^10+\]Error = 0.618570850229987920
MAX = 0.293746019796980560,
coefficient of determination = 0.999163073541008860
由曲線配適得到的數學式就能夠開始模擬數值,此時模擬1百萬筆後,經過270組產生直方圖。
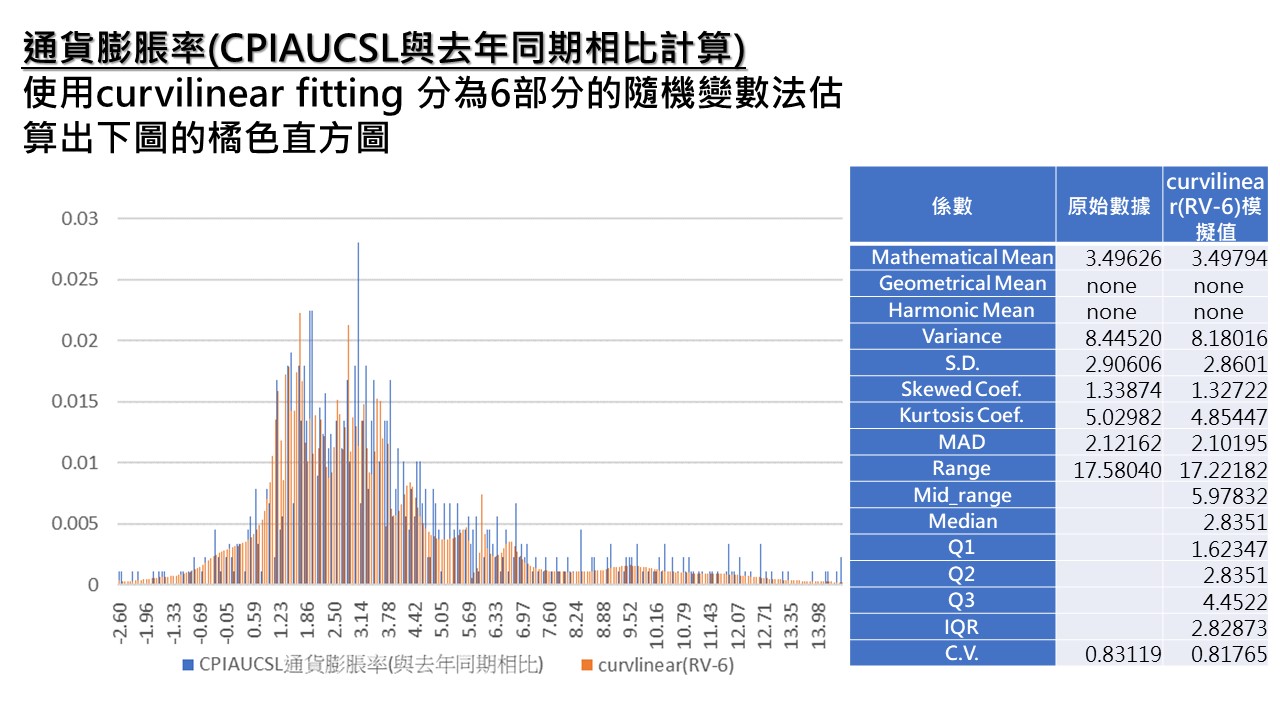
上圖可發現曲線配適得到的模擬值和實際數據的直方圖非常相近。
2.4. 建立數學模型
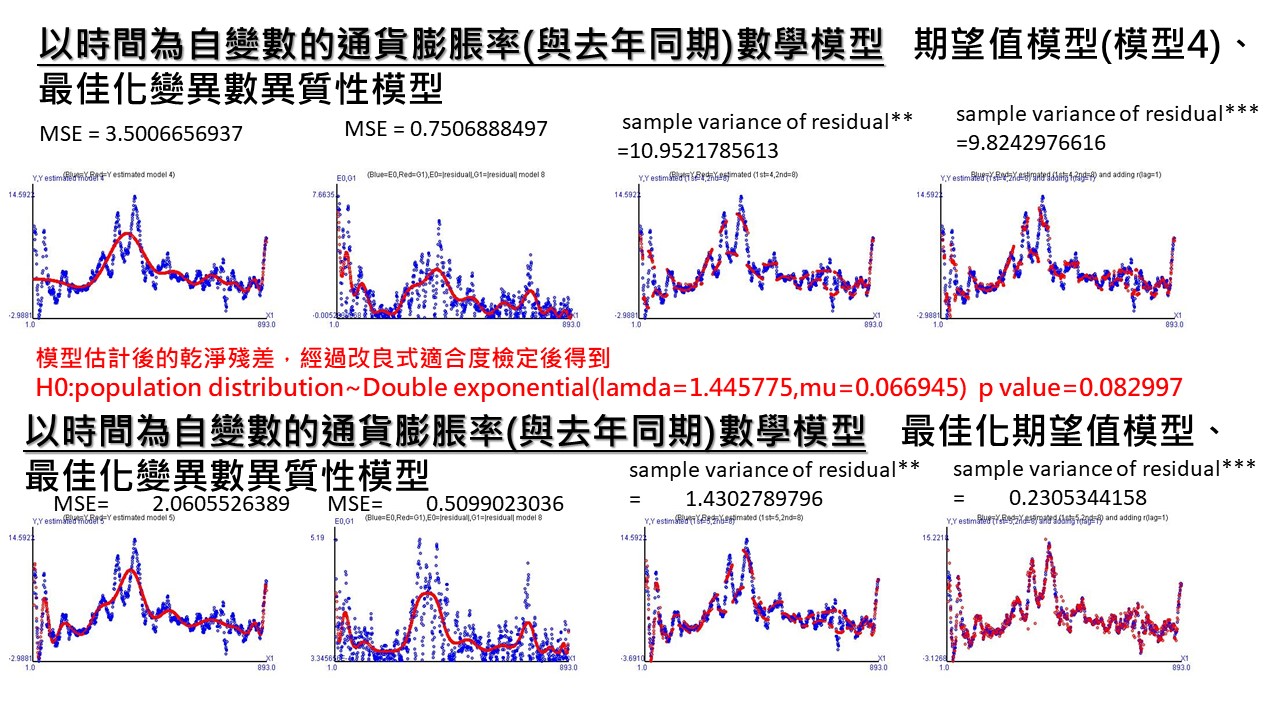
令Y=CPIAUCSL數據的YOY值,視為應變數(dependent variable),X=時間變數,為自變數(independent variable),所以可得到數學式為
\[Y_{t} = H(X_{t})+\varepsilon_{t} \\ Y_{t} = H(X_{t}) \pm G(X_{t})+\delta_{t}\]上式的 $H(\cdot)$ 為期望值模型,$G(\cdot)$ 為變異數異質性模型,$\varepsilon_{t}$ 和 $\delta_{t}$ 為誤差。此處變異數異質性模型中的應變數為 $\vert \hat{\varepsilon}_{t} \vert$ 。
一階自我相關誤差模型的應變數為 $u_{t}=\hat{\varepsilon}{t} / G(X{t})$ ,數學式為
\[u_{t} = \rho \, u_{t-1} + \phi_{t}\]其中, $\rho$ 為自我相關係數(autocorrelation coefficient),$\phi_{t}$ 為我們可以得到的最乾淨誤差。
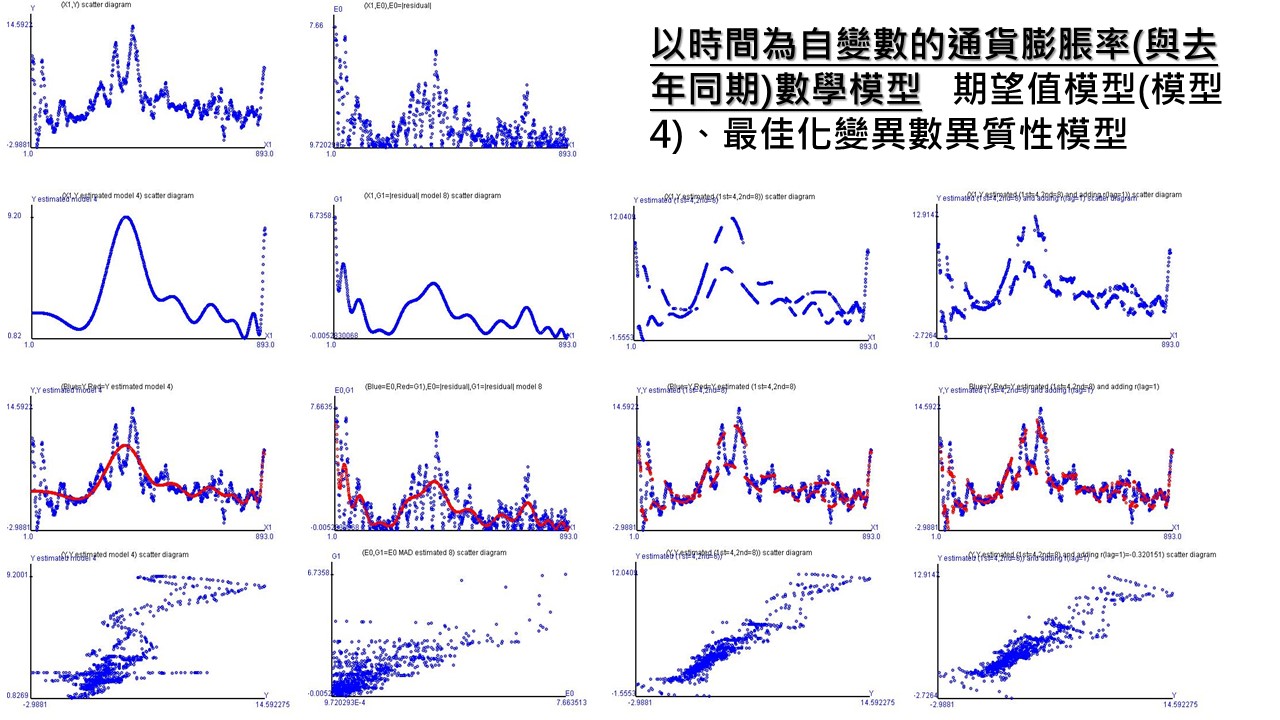
上圖各欄分別為
- 第一欄為期望值模型
- 第一圖:美國每月通貨膨脹率的走勢圖
- 第二圖:美國每月通貨膨脹率的期望值估計圖
- 第三圖:合併第一和第二圖
- 第四圖:美國每月通貨膨脹率和估計值的關係
- 第二欄為變異數異質性模型
- 第一圖:期望值模型得到的殘差,取絕對值後的走勢圖
- 第二圖:變異數異質性的估計值
- 第三圖:合併第一和第二圖
- 第四圖:殘差絕對值和變異數異質性的估計值的關係
- 第三欄為期望值模型 + 變異數異質性模型
- 第一圖:美國每月通貨膨脹率的估計圖
- 第二圖:美國每月通貨膨脹率數據和估計值圖
- 第三圖:美國每月通貨膨脹率數據和估計值的關係
- 第四欄為期望值模型 + 變異數異質性模型 + 一階自我相關誤差模型
- 第一圖:美國每月通貨膨脹率的估計圖
- 第二圖:美國每月通貨膨脹率數據和估計值圖
- 第三圖:美國每月通貨膨脹率數據和估計值的關係
使用最佳化的模型方法可以看出變異數一直下降。而得到的 $\phi_{t}$可經由改良式適合度檢定得到雙倍指數分配。
3. 變異數異質性模型的特性
因為這是通貨膨脹率,所以選擇變異數異質性模型的波動上漲或下降代表,以下為波動上漲的期間:
- 1949年02月~1950年12月
- 1954年06月~1957年03月
- 1963年07月~1977年02月
- 1986年06月~1990年02月
- 1996年06月~2009年07月
- 2014年03月~2016年09月
- 2019年01月~2020年11月
- 2021年12月~
| 模型切割的時間區段 | 美國衰退期 |
|---|---|
| 1949/02~1950/12 | – |
| 1954/06~1957/03 | 1957/07~1958/03 |
| 1963/07~1977/02 | 1969/11~1970/12 1973/10~1975~03 |
| – | 1979/11~1980/06 1981/07~1982/11 |
| 1986/06~1990/02 | 1990/07~1991/03 |
| 1996/06~2009/07 | 2001/03~2001/11 2007/12~2009/06 |
| 2014/03~2016/09 | – |
| 2019/01~2020/11 | 2020/02~2020/04 |
| 2021/12~ | – |