AI新知力系列
統計學本質和架構筆記 - 108 實驗設計這樣玩
從統計學的核心 - 母體和樣本 - 中,我們了解樣本帶著母體特徵,是為了找尋母體。想達到目的需要將樣本轉為統計量,產生抽樣分配,然後才能開展出統計分析。不過,統計分析只能做到兩兩相比。想要再多就沒辦法了。於是,實驗設計上線了。
實驗設計的概念
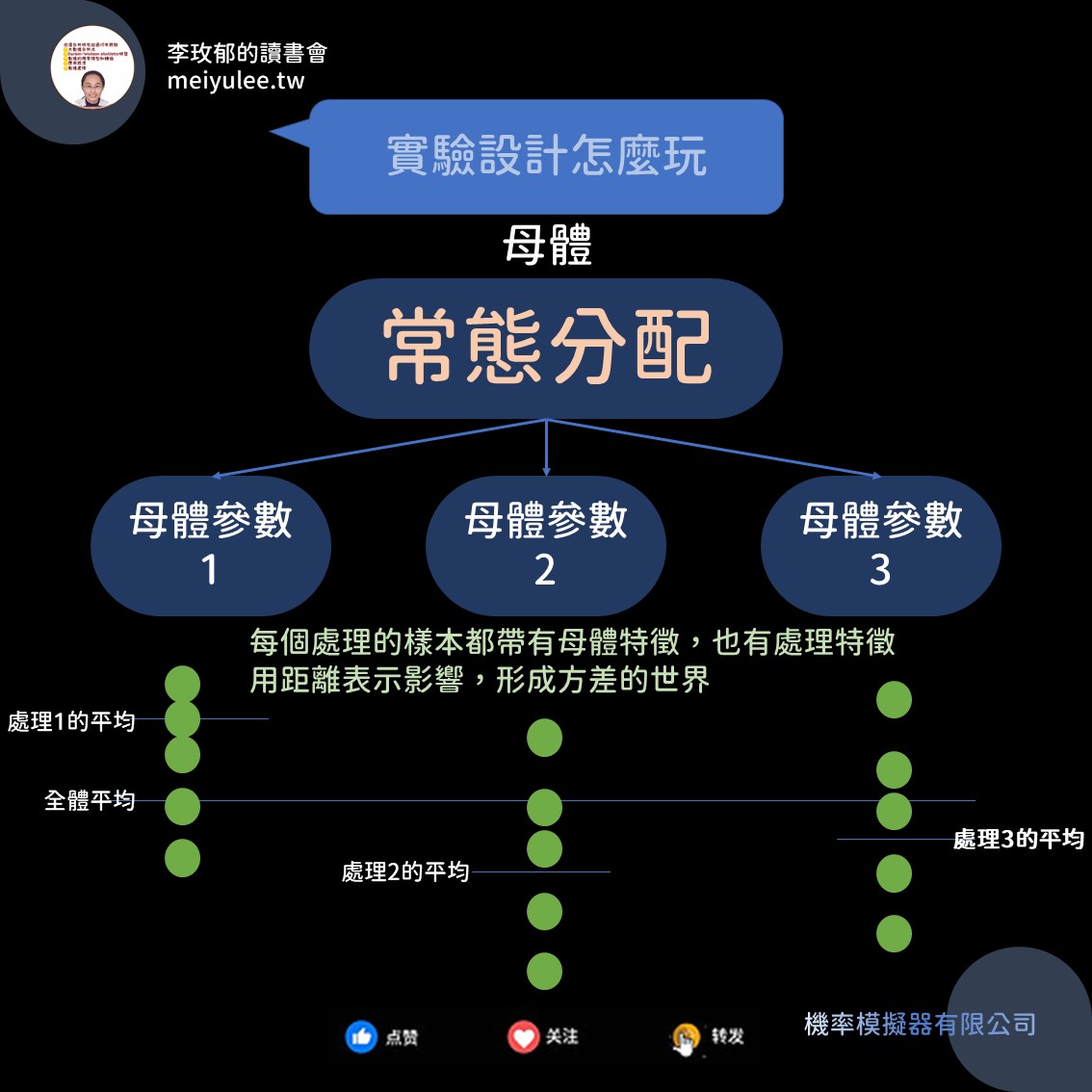
實驗設計整個架構是基於常態分配下,做母體平均的比較異同。那如何產生多個母體平均呢?這就是實驗設計的精神,也是萬法不離宗的,它們頭上都是同一個母體!
在來源處都是同一個常態分配下,將其根據主觀角度對母體做切割。如下圖般,我用一個角度切割出三個子母體,你可以想像是產品來自三個同質廠房。此時子母體有它們各自的特徵。所以樣本就會帶著原母體的特徵,還有子母體的特徵。
容易想像點的方式就是一塊水果蛋糕,你分成三塊,每一塊都是蛋糕,但裡頭包不同或相同的水果塊。
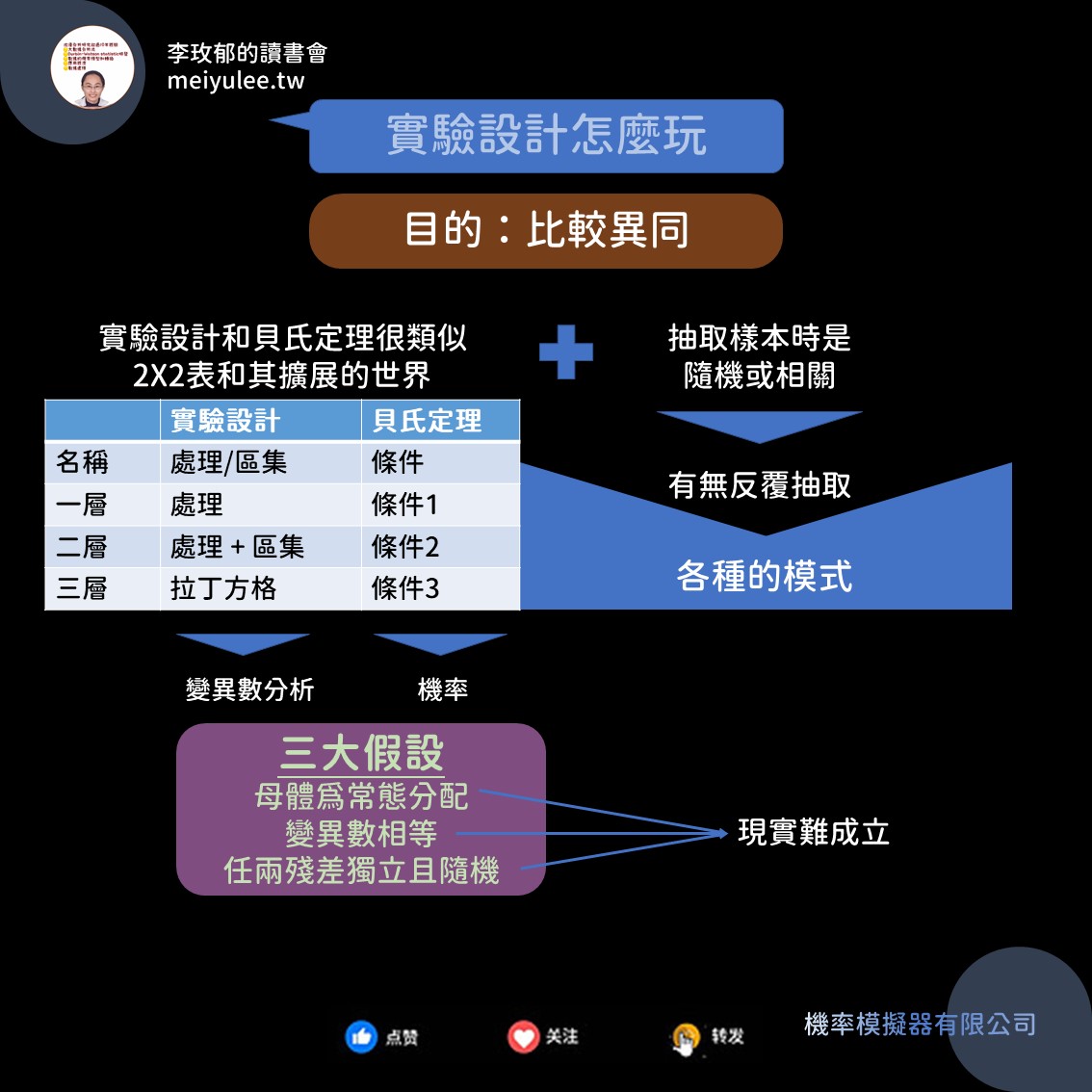
正統點對子母體的稱呼為「處理」。如果還要繼續切第二個角度進來,就會叫做「區集」。對完整學過統計學的人來說,這樣的概念和學習「聯合機率」、「條件機率」、「貝氏定理」所用的2X2表是相同意思的。
實驗設計的模式變化
實驗設計相當於從母體常態分配中做不同角度的切割,然後檢測特定角度切割是否造成異同。你可以選擇一個角度切割母體,這稱為「一類因子分析」。裡頭因樣本獨立又分為
🔵固定模式:子母體的平均之和為0
🔵隨機模式:子母體的平均來自常態分配,平均數=0,變異數為特定值
另外,樣本是相依情況下,稱之為「一類因子且反覆抽取」模式。所以一類因子分析會有3種模式。
同樣,多一個角度切割就得討論該角度是否造成異同。此時稱為「二類因子分析」。這裡又會重複一類因子的做法,同樣也會有三種模式。其中最後一種樣本相依的情況,會多一個兩個角度的交互作用影響因子。這模式很常被使用,討論交互作用有無影響。
同樣,再次加一個角度進去,形成「三因子」。這時候稱為「拉丁方格」。到了三個角度的要求就多了。
- 三個因子的分類個數要相同
- 總樣本個數是分類個數的平方
- 抽取樣本方法須在任兩個因子的交集下,在第三個因子的不同分類中抽出一個樣本
這麼多種的模式,如果用統計套裝軟體跑,一下就完成了。你要做的只是解讀報表而已。
實驗設計可以不受假設限制嗎?
答案是不行的。
第一是在統計分析或大數據分析時,特別是要遵守第二個假設:變異數相等;和第三個假設殘差隨機且獨立。
如果不滿足假設,即使得到變異數分析表(ANOVA),分析結果都不可當真。實驗設計的使用條件較為嚴格!若看到問卷調查使用變異數分析在比較異同時,請先詢問他們是否做了假設滿足與否的測定。
第二是實驗設計適用小樣本,也就是樣本數不多的情況。
這是一套利用少數樣本去看某角度分類是否存在影響母體平均數的可能性,由個人主觀認定有角度分類有影響的立場去抽樣,再對樣本做假設檢定,分析造成差異的原因。認為增加樣本提高實驗設計滿足假設的方法是不可行的。
適用小樣本的方法就是小樣本的方法,想要拉到大樣本或大數據分析上,就需要調整。但調整的方法需要在不同的樣本數量下去測定出來。這點是水磨功,很少人願意做。
實驗設計方法
整套實驗設計設計出各種的模式,其方法最終要建立變異數分析表。
之所以採用變異數是因為實驗設計要探究角度分類是否影響母體平均,而影響就從距離產生。每個樣本和處理的平均、和全體的平均,產生了組內和組間的差異。
在分類之間所產生的差異較做「分類」。例如,我分了三類,也就是三個子母體出來。每個分類的平均數和全體平均產生了距離,將之轉換成平方和型態 (SSTr)。
全體數據都是來自母體,所以可以得到所有樣本和全體平均的距離,再轉為平方和型態(SST)。
來自誤差的差距則是樣本和各處理的平均產生了距離,將之轉換成平方和型態(SSE)。
三者之間有等式關係:SST = SSTr + SSE。也由此產生變異數分析表。
| 項目 | 自由度 | SS | MS | F |
|---|---|---|---|---|
| 處理 | $k - 1$ | SSTr | MSTr | MSTr / MSE |
| 誤差 | $n - k$ | SSE | MSE | |
| 總和 | $n - 1$ | SST |
實驗設計從多個母體平均檢定,到任二個母體平均檢定(稱為多重比較法,或Post HOC法),了解當至少有一母體平均不相等時,那母體平均的排序大小就靠後者完成。
至於,實驗設計需要對假設的檢定,我就直接歸納如下:
- 檢定是否為常態分配:適合度檢定
- 檢定是否同質變異數:Bartlett法
- 檢定殘差是否隨機:隨機性檢定(Run test)
對此有興趣的朋友們可以再深入研究。