AI新知力系列
統計學本質和架構筆記 - 109 實驗設計讓AI思考
上一篇《實驗設計這樣玩》說完實驗設計的目的、概念、方法。內容不涉及計算和公式,因為最終統計套裝軟體可以直接幫你跑完,產出報表來。所以,需要的是對實驗設計的本質和架構有所了解,特別是假設一定要成立,不成立的話分析再多也沒用。
我為何要分享到實驗設計呢?一個用於比較異同的方法而已,被廣泛地使用,又不能創造出什麼新玩意!
其實我是為了這篇文章分享而鋪陳的。在上篇文章我也提到了實驗設計其實和聯合機率、條件機率等是有關係的,只是解法、走向不同。那麼這篇文章,我的主題就是實驗設計是能夠幫助AI思考的核心!你相信嗎?
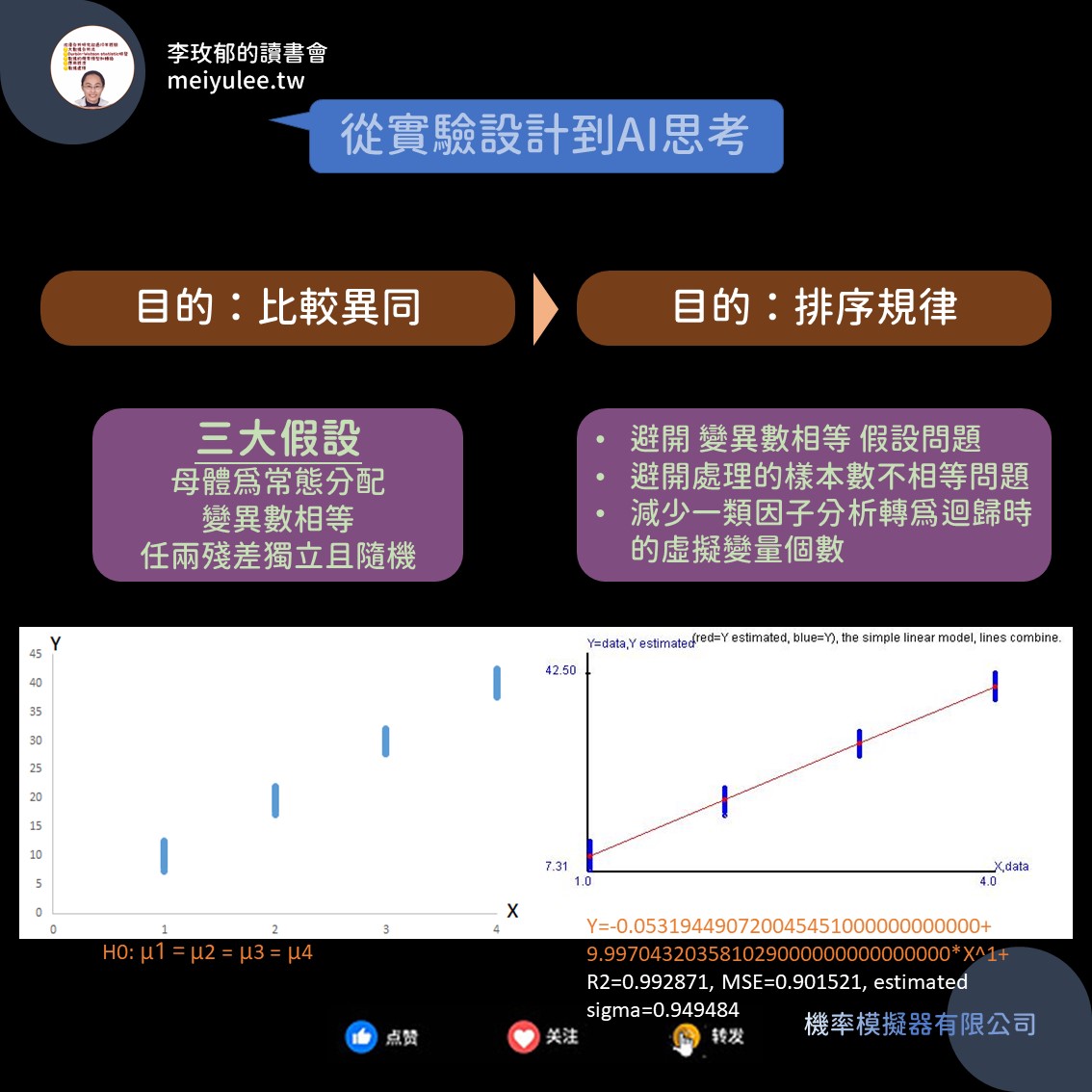
簡單來說,原本實驗設計是將母體用不同角度去切割,產生了子母體。子母體的特徵是否會對母體平均產生影響是其核心的問題。那和AI有什麼關係?
此時,我們要脫離比較角度分類造成的異同,轉到角度分類為核心本質的基礎上去看。上圖的左圖就是我們常見的實驗設計樣本圖。它的分類出現在橫軸,以數字表示。橫軸的數字是你可以任意認定為哪一組數字群。
上圖所設定的4個樣本群組分別為:
- 群組1:Y=10+誤差1,
- 群組2:Y=20+誤差2,
- 群組3:Y=30+誤差3,
- 群組4:Y=40+誤差4,
誤差1、2、3、4來自常態分配,平均數=0,標準差=2。
每組皆有100個成對樣本,所以全部的樣本數為400個成對樣本。成對樣本形式 = (X, Y) = (群組代號, Y)。
於是,我們可以根據群組代號和Y值,為它們建立精準的數學模型 (見上圖中的右圖紅線)。這種精準模型不能使用直線,得要是曲線,曲線將包含直線型態。
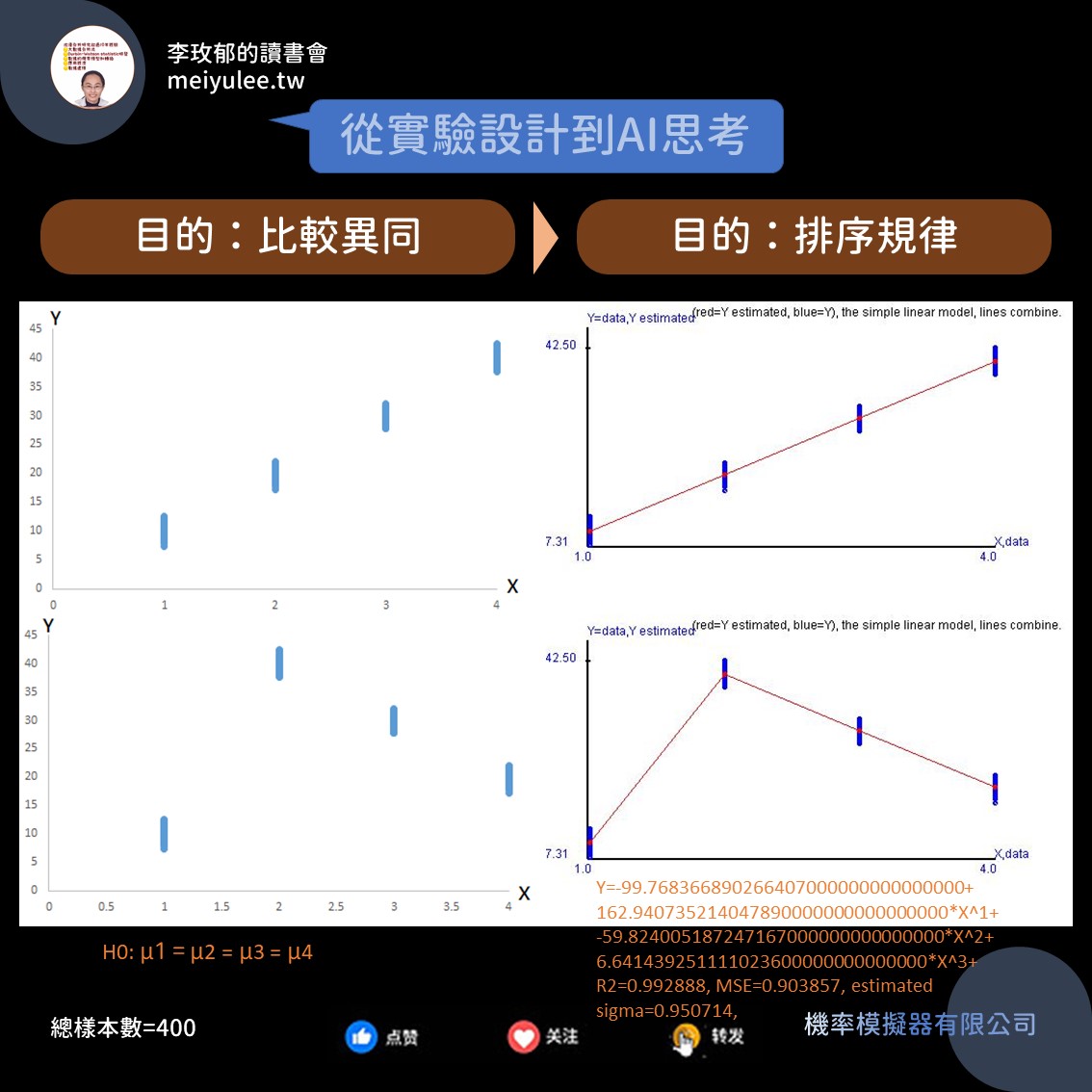
對群組的排序是可以改變的。現在將先前的4個樣本群組分別設定為:
- 群組1:Y=10+誤差1,
- 群組2:Y=40+誤差2,
- 群組3:Y=30+誤差3,
- 群組4:Y=20+誤差4,
就只改變了先前群組的排序,其他都不改變。在每群組樣本皆為100個下,可以建構精準數學模型,得到上圖中的右下圖。數學式相對複雜,但能真實抓出群組平均數的位置和規律。
數學模型有什麼用?
目前生成式AI最大的問題就是其結果沒有數學式,自然你想要AI的結果可以預先模擬和驗證都做不到的。而數學模型能改變這一切。就使用實驗設計方法的分群組,恰好就是生成式AI資料庫內的核心之一。而現在需要做的是讓文字、語音(詞組音),或圖像色階位置全數編號。
例如,色階顏色可以用連續伯努力分配形成可累加的數字。圖像的色彩位置為群組代號。我們就根據群組代號排序出不同色階顏色形成的數學規律,就連圖像未知的畫面也能用數學模擬出來。
所以就上圖來看,上方的實驗設計群組排序的順序會讓你知道下一個群組代號如果出現,它的平均數將會落在哪。而下方的實驗設計群組則會讓你知道群組排序的下一個群組代號平均數位置會在哪。
如果有足夠的下一個群組樣本,就能連其離散程度都抓出來,為整個群組建立分配。
如果不知道下一個群組代號的離散程度,則可使用「假設分析」法,為其建立各種離散程度下,但已可預估的平均數位置的分配。
只要你用到第5個群組代號,那麼就有機率落在正確的分配內。然後AI就能去驗證哪個分配比較可能是第5個群組代號分配。
當AI的資料庫內充滿了這樣的數學模型後,AI想要思考就不是難事了。
結語
實驗設計原本是為了實現比較異同的解決方法,但當我們觀察其本質後會發現,分類分組是AI的資料庫核心,而群組分類的代號做為排序用,就能建立排序的規律模式。用數學模型能夠精準且細緻地操作更多,加上貝氏定理早已存在,AI在下一個群組代號的平均數位置或分配型態是可預期地會成功出現。
隨著匯入的數據愈多,就能發現此規律和規律改變情況。輔以使用「假設分析」法建立各種的假設可能,為其事先建立的數學模型。等到真實的樣本進入就能進行比對和調整。而上圖中的紅線,其實就是所謂的通則,離散程度形成了個別化。
如此一來,實驗設計的本質將出現重大的翻轉,成為建立排序規律的數學模型工具。至於AI內的各種分類排序因人而異,實驗設計的方法轉換成排序規律可以有效為AI的分類排序建立數學模型,還能避開實驗設計中的假設限制,以及實驗設計和迴歸分析互通時需要設定多個虛擬變量問題。
你的學的實驗設計方法更新了嗎?用多線段法的曲線直線模式建構分類下的排序規律將會顛覆AI。
你的AI不只解決自動化流程,還將能思考!