1. 前言
我前面已經寫了如何做《45種機率分配的適合度檢定》和《已知機率分配的適合度檢定》,這個方法從45種機率分配中檢定出合適於數據且知道參數的機率分配。不過,有時我們已經都知道機率分配和分配參數仍希望檢測看看數據是否服從此機率分配,就能夠使用第三個選項。
不過,有時我們可能只需要知道數據的機率分配對應的參數為何,這篇文將說明第三種的適合度檢定:已知數據的機率分配和分配參數的情況。
2. 軟體操作
在開啟軟體並選擇數據檔案後,選單畫面鍵入【3】後,點擊【end】上方的圓點。
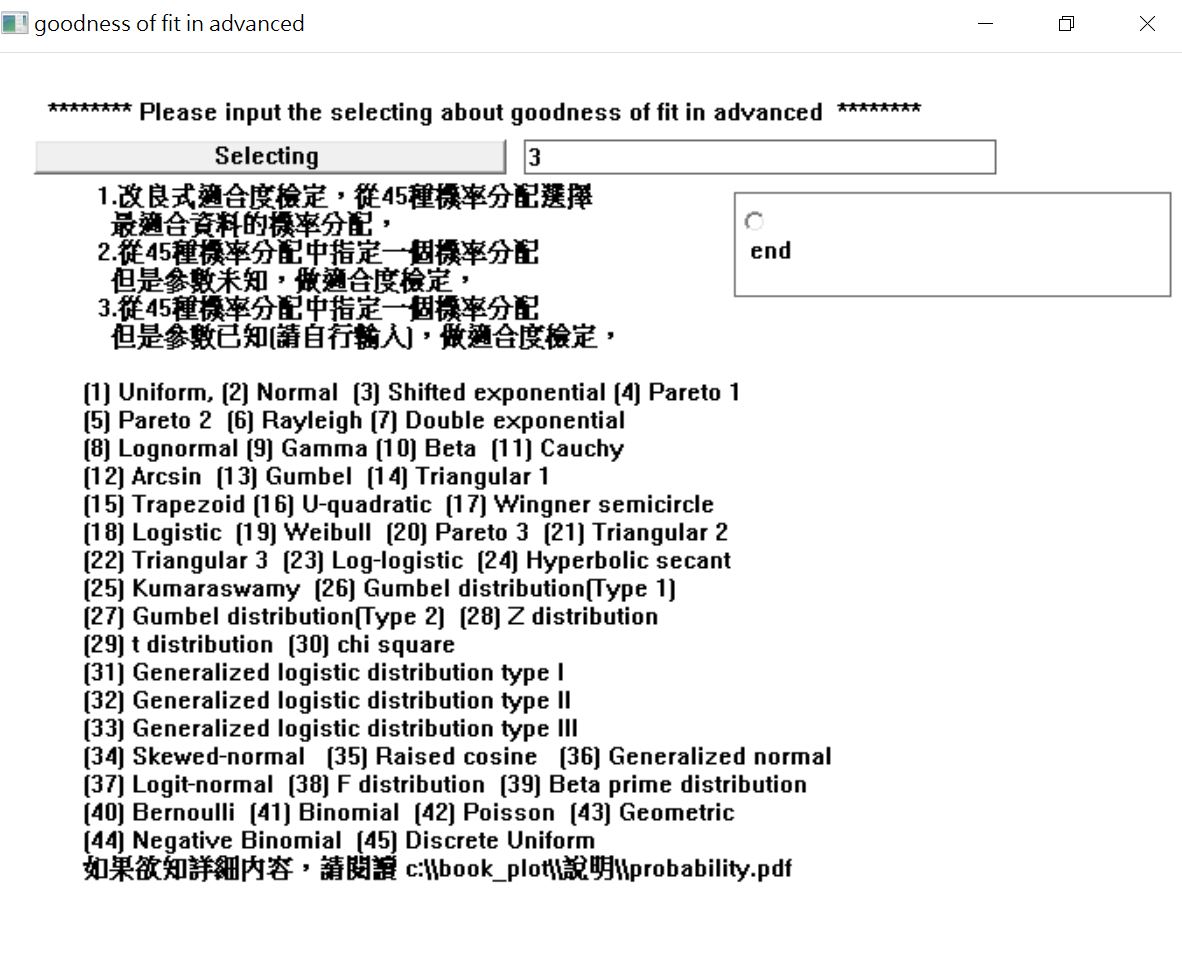
軟體會跳出提出視窗。點擊【是】後,繼續下一步。
點擊【是】後,繼續下一步。跳出新視窗顯示數據的敘述統計係數。
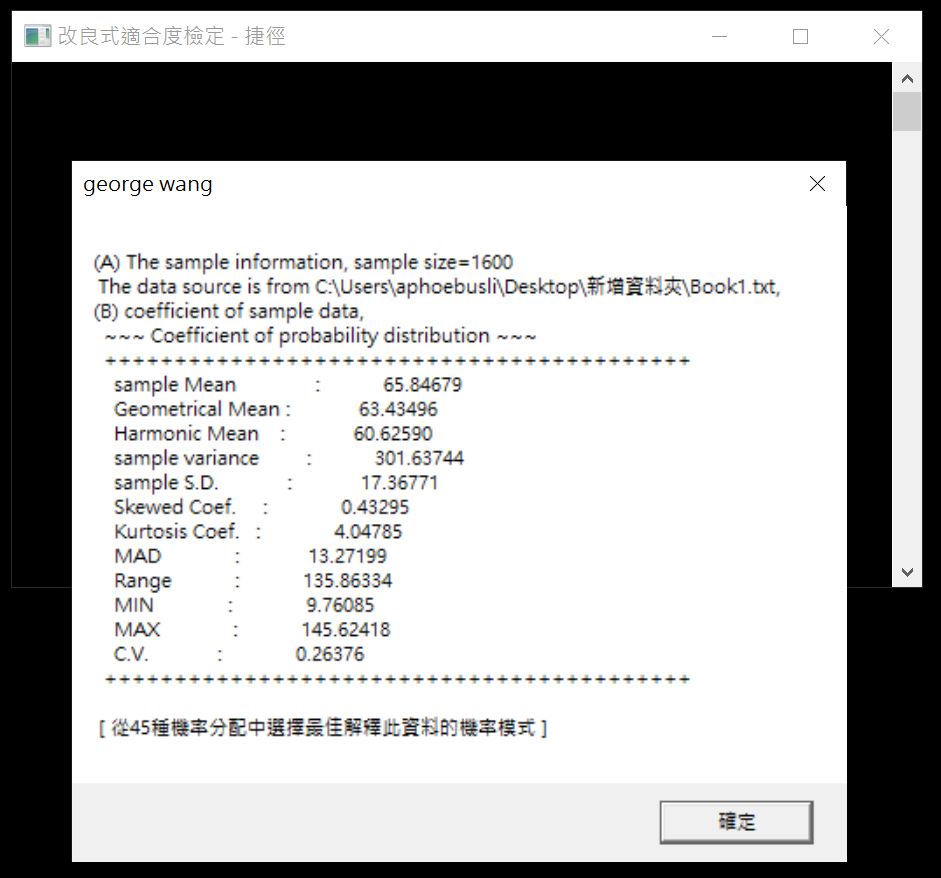
點擊【確定】後,繼續下一步。此時,我們因為已知機率分配且已知係數。鍵入【31】、然後鍵入參數值。第一個係數應該是58,第二個係數應該是11.1,第三個係數應該是1.6。但我這邊改變了第一個和第二個係數。
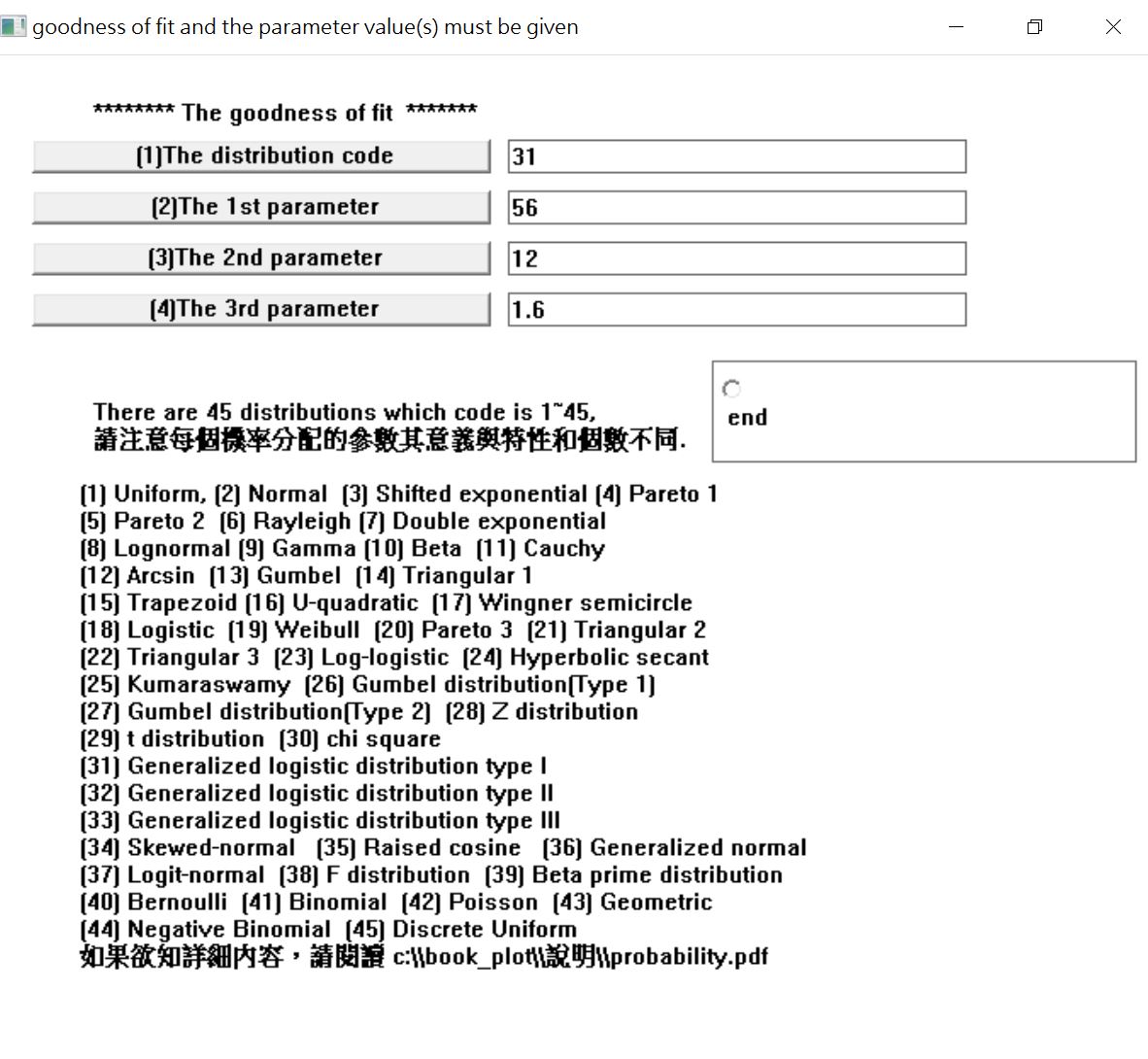
鍵入完畢點擊【end】上方的圓點後會跳出下圖。確認輸入的參數是否正確。
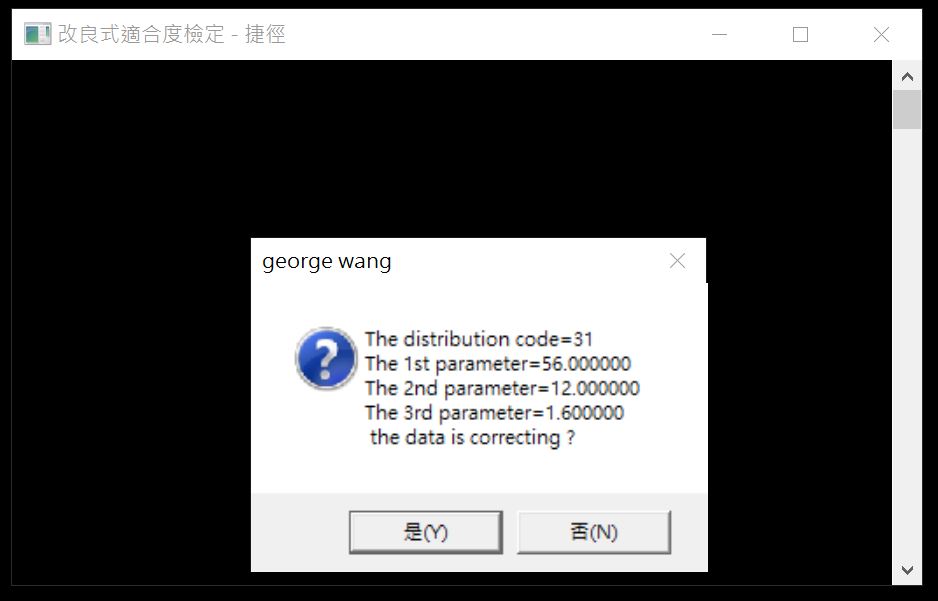
點擊【是】後,繼續下一步。軟體開始運算。
運算適合度檢定完成後,跳出視窗顯示下圖的最佳結果。

點選【確定】後,繼續下一步。新視窗提示軟體已經運算完畢。
點選上圖的【確定】後,軟體關閉。
完整的運算結果儲存在 C:\建模軟體\輸出\statistic_output.txt。
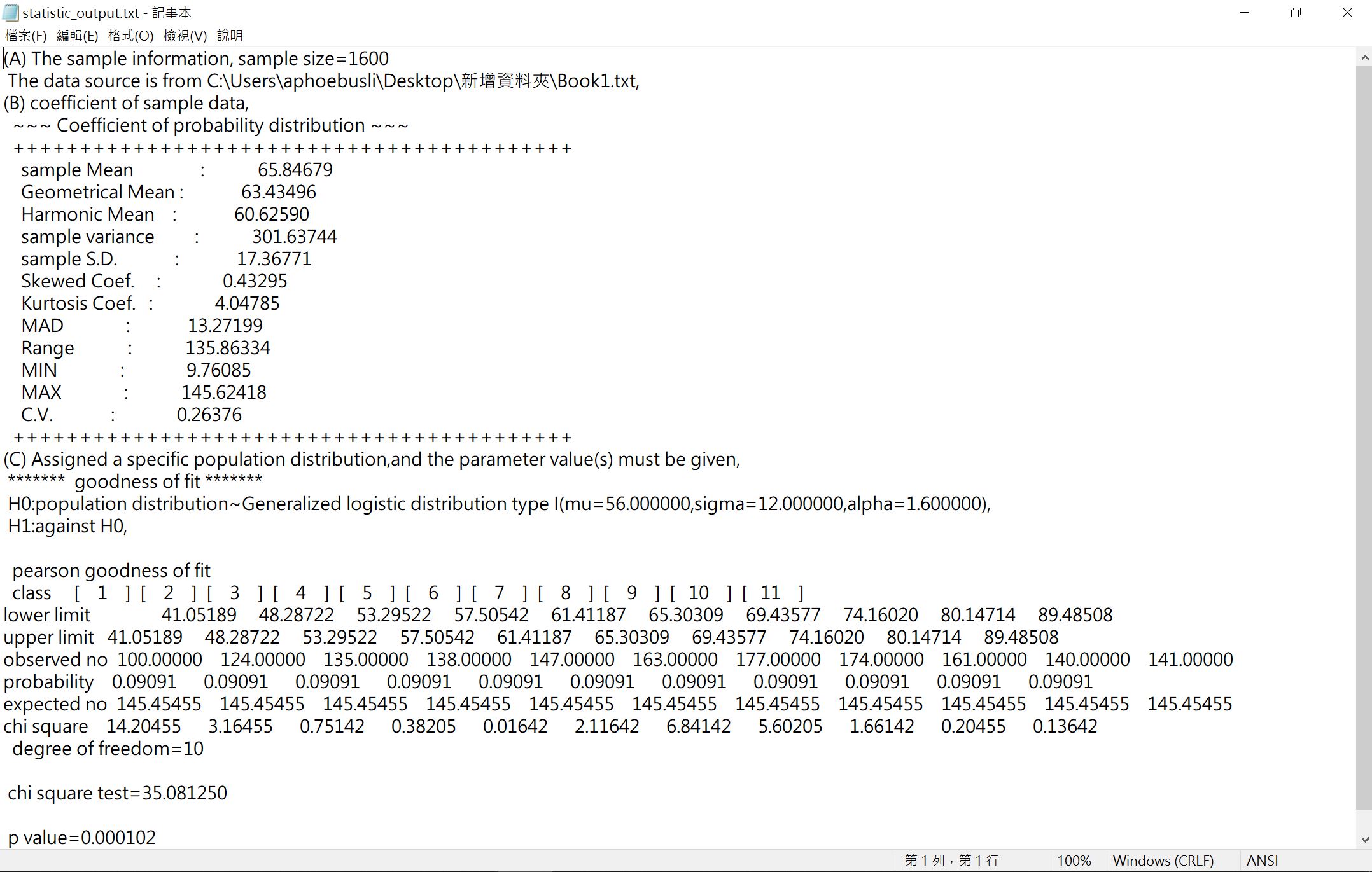
我們打開儲存的檔案就可看到上圖。由於我設定一般羅吉斯型I分配,但參數中有兩個並非第一種方法得到的數字,所以經過適合度檢定後,可以得到的P值=0.000102 < 0.05,拒絕虛無假設,代表一般羅吉斯型I分配和我設定的參數值,無法通過適合度檢定,亦即數據不是服從我設定的參數。
那麼如果我使用第一種方法檢定出來的參數值呢?我設定參數分別為58, 11.1, 1.6後,經過第三種適合度檢定的設定,得到下圖。
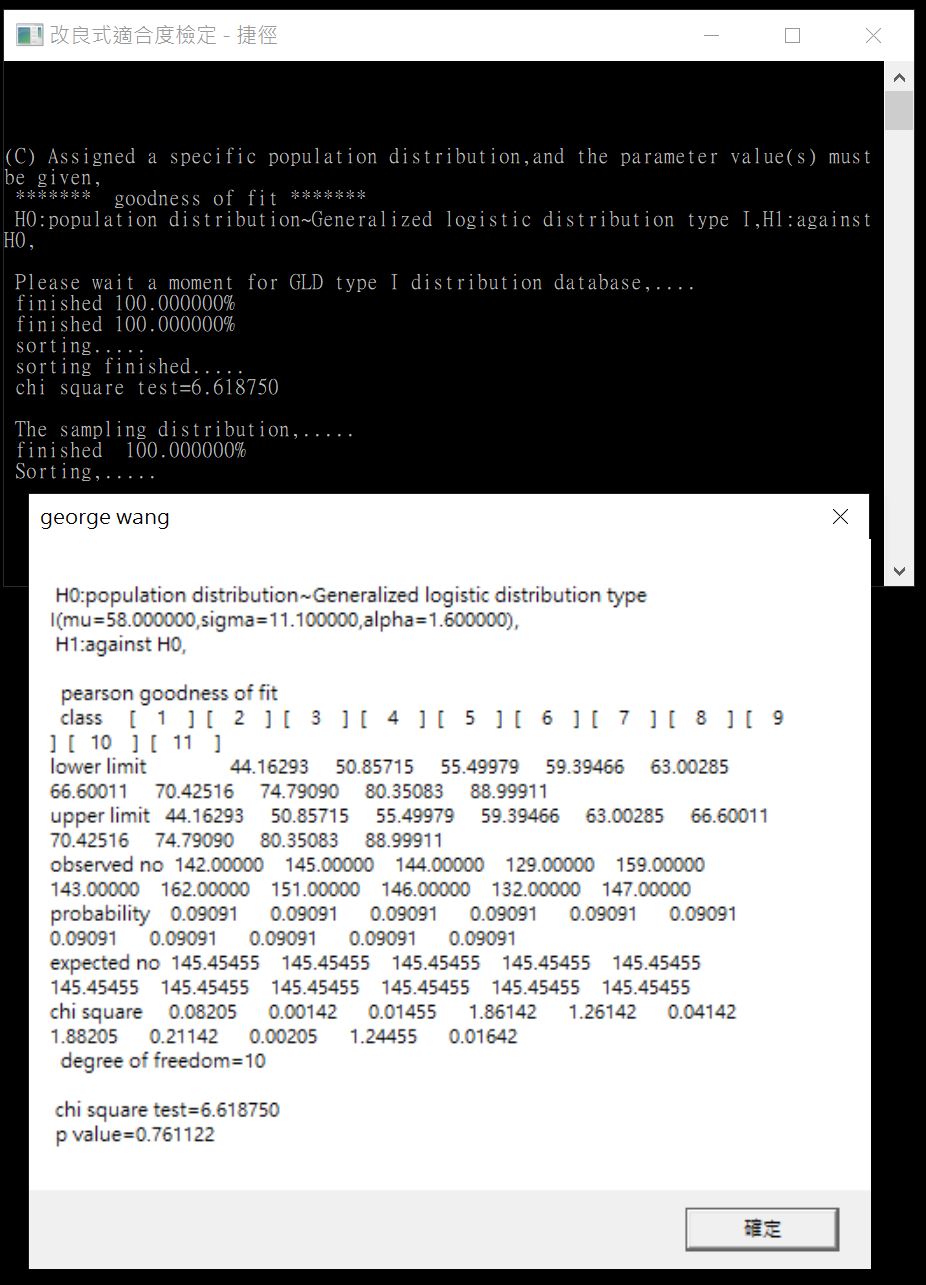
適合度檢定的結果是P值= 0.761122 > 0.05,數據無法拒絕虛無假設。此時,這些分配參數設定是顯著水準下無法拒絕虛無假設的結果。我們可以說數據來自一般羅吉斯型I分配,參數為 $\mu=58, \sigma=11.1, \alpha=1.6$。
小結
適合度檢定時需要注意到虛無假設的機率分配和分配參數是否已知。如果我們都不知道數據服從何種分配,使用第一種方法,從45種機率分配測定出數據服從何種特定參數的機率分配。
若已知數據來自某特定分配,但參數未知時,我們可以使用第二種方法測定出分配的參數。不過機率分配有時候是可以相通的,所以,在特定分配和特定的分配參數下,可能會有兩個(或多個)分配是數據來源。
若已經使用其他軟體或程式知道數據的機率分配和分配參數,但還想用這個軟體測試看看,就將已經知道的機率分配和分配參數依循本文的方法設定好了,最後結果即可知道是否數據來自此特定參數的機率分配。
對大數據和人工智慧而言,建立機率模型是非常重要的。機率模型=機率分配,但適合度檢定能夠檢定出來的屬邊際機率分配。邊際機率分配可為事前機率分配。這意味著,使用大數據或人工智慧模型的專家學者應遵從數據告知的分配,而非看數據的直方圖認定特定的機率分配。後者方法尺產生的錯誤從未被使用者意識到,而錯誤是大還是小也沒人知道。因此,現行的大數據和人工智慧模型皆有其侷限性。
從我分享的三篇文章已經揭露了大數據和人工智慧模型應該被改善,由數據驅動得到機率模型,不再是人為認定或人為識別。