1. 前言
我們手邊常常有數字類型的數據,但我們如何才能知道數據的特徵呢?很多人在做統計分析時並不瞭解統計到底在做什麼。如果你還不清楚統計的目的,點擊「機率和統計關聯」,先了解統計和機率的關係,就能知道使用統計的分析的目的何在,以及為什麼我們會說機率是統計之母的原因。在你了解機率和統計關聯後,接下來你才會了解圖解說明的區間估計。
2. 區間估計定義中的三個重點
回到本文主題,區間估計是利用隨機樣本的數學組合,在一定的可信度下,建立一區間。我們將用這個區間「了解」母體分配參數的方法。根據這段話,我們可以歸納出三個重點:
-
你手邊的數據就是隨機樣本,你要將隨機樣本做數學組合,變成一個新的變數。這個新的變數通常是平均數或變異數,如果是二分法的分類型變數,那就是比例(proportion)。比例型的數據通常要先做分類,再計算特定分類的佔比。
-
在一定可信度下的可信度又稱為「信心水準」,參考圖3可知信心水準就是機率值。區間估計需要先知道這個機率值。通常是人為自己認定的 90%,95%或99%。在市場調查或民意調查中最愛使用95%。如果樣本數夠大到使用「中央極限定理(central limit theorem)」,Z分配的臨界值就是 $Z_{0.025}=1.96$ 1。
-
建立區間是因為多次的隨機試驗產生了誤差,區間估計使用$E$代表此誤差,並稱為「最大誤差(maximnum error)」,它代表在一定的可信度下,樣本的數學組合和母體參數差距的最大容忍上限。
- 最大誤差展現出區間估計的精確度(precision)。
-
最大誤差在民調中又稱為「抽樣誤差」或「誤差範圍」。 民調的抽樣誤差通常設定比例=0.5帶入到抽樣分配的變異數,並且設定第2點提到的Z分配臨界值。此時的分子固定為0.98,分母則為$\sqrt{n}$。
因比例為0.5的中央極限定理所需之最少樣本數為1000個,所以在計算機中建入除以1000開根號,得到圖1。若樣本數增加,會降低誤差。例如在1451個樣本下,抽樣誤差為2.57% 2。
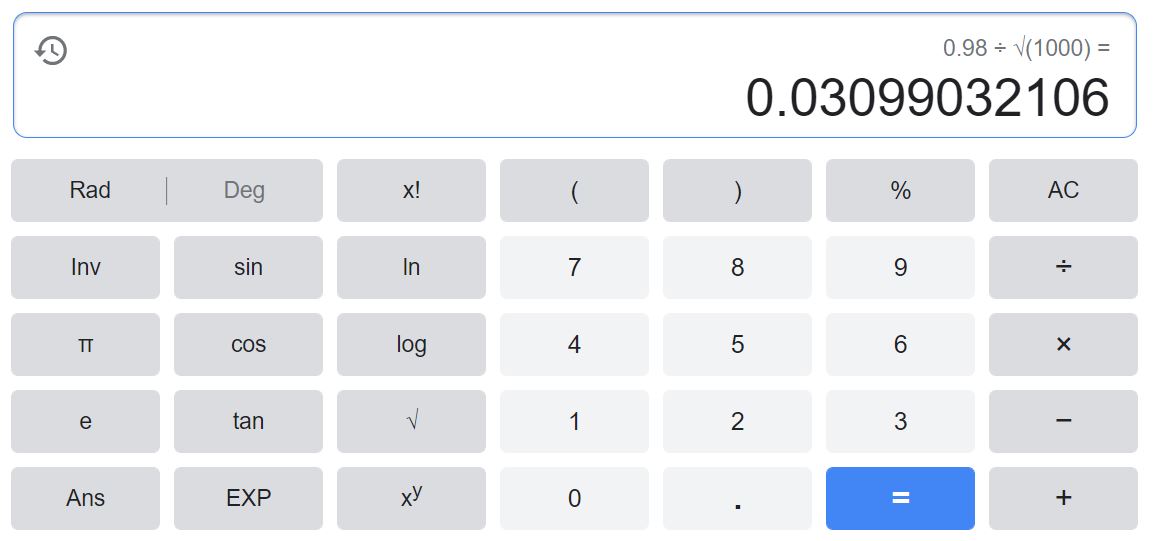
圖1 1000個樣本的抽樣誤差計算

圖2 1451個樣本的抽樣誤差計算
3. 區間估計的意義
區間估計除了上面的三個重點外,我們還要了解區間估計中的三個意義。

圖3 區間估計圖解
-
可信度的意義
可信度在區間估計時需要先知道。可信度即為機率值,代表風險或危險。先設定好可信度代表先控制好自己可以承受的風險和不準確性。 準確性或準確度是指樣本數學組合的數學期望與母體參數的接近程度,反映了測量過程中系統誤差的大小。
-
區間的意義
區間代表使用樣本了解母體參數的精確性。因為了解母體參數的過程中存在隨機性,而有隨機誤差。這個誤差形成區間範圍。區間愈窄愈好,代表離散程度小。精確度指測量值與其數學期望之間的離散程度,反映了測量過程中偶然誤差的大小。
如何解讀?
- 公式角度 母體參數包含在區間內的機率為 $(1-\alpha) \times 100$ %。
- 多次試驗 經過多次試驗後,產生了平均結果。因為機率代表事件發生的頻率,100次中平均 $(1-\alpha) \times 100$ 次母體參數包含在區間內。
- 一次試驗 一次試驗只會有兩種結果,母體參數包含或不包含在區間內。此時的機率值只會有兩種不是0就是1。
-
試驗結果的二分法 區間將結果二分為「成功」或「失敗」。
- A事件=母體參數包含在區間內=成功;
- 非A事件=母體參數不包含在區間內=失敗。 $P(A)=P(成功)=1-\alpha$ $P(非A)=P(失敗)=\alpha$
4. 小結
區間估計是統計學中的比較方法,架構在使用信賴區間產生的二分法中,形成母體參數包含在區間內的成功事件和母體參數不包含在區間內的失敗事件。在區間估計的定義中的三個重點分別為樣本的數學組合、可信度、區間。區間的造成來自多次隨機試驗產生的誤差。這讓點估計和區間估計產生的差異。
- 點估計:專注精確度
- 區間估計:考量精確度和準確度($E$)
而區間又有三個意義,分別為多次試驗帶來的母體參數包含在區間的機率意義,以及平均而言母體參數包含在區間的頻率意義。做一次隨機試驗的成功和失敗意義。
區間估計的最大前提是:你得先設定可信度。接著多次隨機試驗後應滿足預先設定好的可信度。
實際情況可能發生此區間範圍反推得到的機率值 $\neq$ 可信度。此時我們就須檢討信賴區間範圍可能發生問題。這是一種驗證的方法。然而,目前幾乎沒有數據分析人員願意將區間估計結果進行驗證,而採取直接相信。這導致了生活中充斥著非常多的錯誤數據分析結果。
參考資料
-
實際的民意調查中,已經改用有效樣本,而非實際抽樣樣本。所以抽樣誤差受樣本數不同而調整。參考《什麼是抽樣誤差?老師和媒體都沒教你的那些事》。有效樣本的設計中充滿人為干預的權重概念,此導致的偏誤未被納入考量。因此,我在內文中並不提有效樣本。若依循一開始的母體設定,要求對應之抽樣方法正確執行,直接使用樣本即可。 ↩