AI新知力系列
統計學本質和架構筆記 - 107統計分析三套件的關聯
學習一個學科知識先知道整體架構是非常重要的。能夠先了解知識內容的架構,就能切割成小碎片,一片一片地學習。
當初我學統計學時是跟著老師的進度學習,而有些進度內容的關聯得靠老師願不願意說,不然就得自己慢慢琢磨。我很幸運地遇到的老師會在這些關聯和切割小碎片時反覆地說,反覆地帶題。而我分享的則是我吸收後的想法,搓揉後,形成我的知識地圖,這內容和正式的學術專業知識有所差異。
今天就分享統計三套件的關聯。我也在上篇文章回應朋友的留言說:「從一次試驗結果(點估計)到n次試驗結果(區間估計),再到希望在n次試驗下用人為一刀二分的Y/N懶人法」。
這是個很簡化的說法。統計分析三套件的源頭是統計量。統計量因多次試驗,產生抽樣分配。統計量和抽樣分配就是三套件運行的重點。好在統計分析的抽樣分配都是常態分配系列,Z、t、卡方、F分配。但如果你想走到大數據分析和人工智慧,105篇的45種機率分配就得了解。統計分析就是套方法,不用限制在傳統統計分析上。
如果你還沒看過前6篇筆記,可以先複習一下喔。
101《認識統計學的兩大板塊》
102《了解統計學兩大板塊關係》
103《機率分配參數代表母體特性》
105《無母數可以變成有母數》
106《你的統計分析三套件上線了》
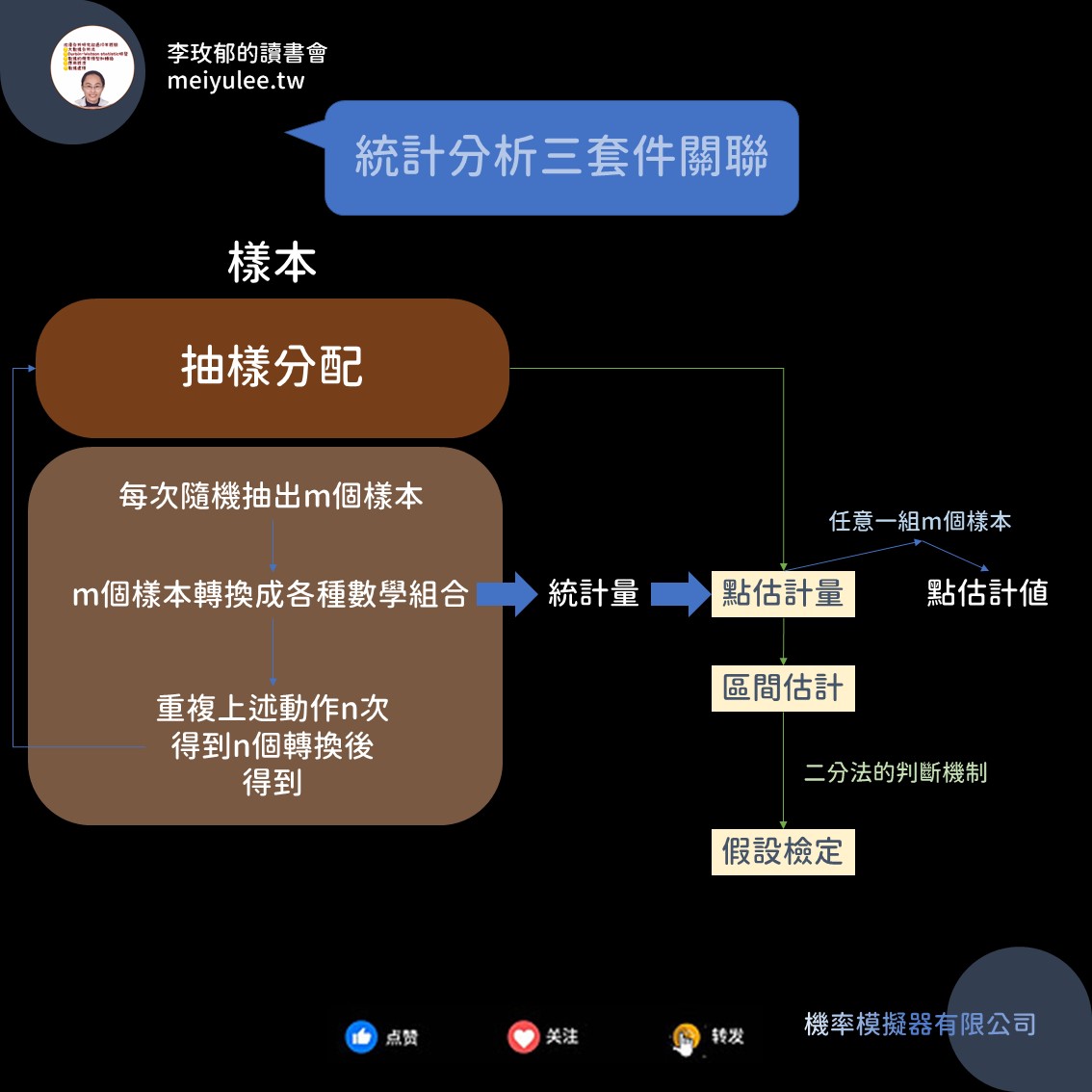
用上圖分享統計分析三套件關聯
根據前面的概念,統計分析的源頭是統計量。統計量得從樣本而來,是m個隨機樣本的數學組合。點估計量就是m個隨機樣的數學組合。
對我來說,從公式上看是可以畫上等號的。統計量可以是一組m個隨機樣本的「各種」數學組合,到了點估計量,會有其條件(四性),才能成為統計的點估計量。所以你能看到上圖的從左到右的藍色箭頭走向。
為何會有第二個套件 - 區間估計?
這肯定是點估計讓人有所不滿意的地方。上圖的點估計量,經過一組隨機樣本值代入後,只得到一個點估計值。
這表示一個數字代表全部。現在大數據分析和人工智會在數字分析上以敘述統計的表現方式也是同樣道理。
於是專家學者們想到,那不如多做幾次試驗,就像從統計量弄出抽樣分配出來一樣。
他們就乾脆多做幾次試驗,得到n個點估計值。如此一來,就會有隨機性和點估計量更能被人信任。
而n個點估計值會產生平均數和變異數,透過這樣的方式可以消除很多影響,留下更重點討論的關鍵點。
如此就從一個點,擴展到一條線,也就是區間範圍。
為何會有第三個套件 -假設檢定?
同樣的情況再次發生,肯定是區間估計不夠好,才會發展假設檢定。
在區間估計中,放在不等式中間的是母體參數。這是很正確的,因為樣本就是用來找母體參數。可那是區間範圍啊!沒有專業點的訓練想從區間範圍去認出母體參數是多困難的啊。
有沒有更容易點,但不違反區間估計特點的點估計值和變異數的離散保證嗎?於是,統計學發展到假設檢定。不像區間估計的母體參數是在一個區間內,而是直接給它一個數字。在用這個數字代入檢定量後,做判斷可不可被拒絕。
結語
人類的發展過程中,只會往更容易,更方便的方向走。統計分析也是一樣。為了尋找母體參數,從統計量和抽樣分配,到統計分析三套件。整個分析方法服務的就是如何從樣本看到母體參數。
這回到母體上,其實你的問題決定了母體。就像我想知道三個群組之間的差異,那麼母體就會是這三個群組的所有人,然後分群後,各自是群組母體,再找出母體機率分配和母體參數。你可以整個群組討論和分析,也能分成三個群組,以群組母體在各自討論和分析。
上段的內容適用大數據分析和人工智慧,並非侷限在統計分析的常態分配假設上。