一、數據類型與對應分析方法
數據分析是從數據開始的,而數據類型決定了可以使用的分析方法。了解數據類型和相應的分析方法,是成為優秀數據分析師的基礎。
數據類型決定分析方法
數據分析從數據開始,而數據類型決定了你能使用的分析方法。以數字型數據為例,它可以分為累加性和非累加性兩類。累加性數據適用於有母數分析,而非累加性數據則適用於無母數分析。理解數據類型和相應的分析方法,是數據分析的基礎。無論是傳統的數據分析,還是現代的大數據和AI技術,都需要根據數據類型選擇合適的分析方法。
| 數據類型 | 累加性數字 | 非累加性數字 |
|---|---|---|
| 用途 | 實數計算 | 排序、比大小 |
| 代表指標 | 平均數 變異數 |
中位數 |
| 統計學 | 基於常態分配 | 找不到中位數抽樣分配 |
| 分析方法 | 有母數分析 | 無母數分析 |
有母數分析與無母數分析
有母數分析主要處理累加性數據,這類數據可以進行統計量的計算和檢定。常見的有母數分析方法包括估計(點估計和區間估計)和檢定。這些方法基於平均數和變異數等統計量,適用於大多數的數字型數據。而無母數分析則主要處理非累加性數據,這類數據多為排序數據,用於比較大小。由於統計學無法為排序數據的中位數產生抽樣分佈,因此使用無母數分析方法。這類方法不依賴於數據的特定分佈,更加靈活。
大數據與AI中的數據分析方法
即使是現代的大數據和人工智慧技術,也需要根據數據類型選擇合適的分析方法。例如,機器學習算法會根據數據類型選擇不同的模型和方法。理解數據類型和相應的分析方法,不僅有助於選擇合適的工具,還能幫助數據分析師觀察和驗證大數據和人工智慧的結果是否可靠。無論是計量經濟學還是經濟數學,都需要基於數據類型選擇合適的數學模型和分析方法。
因此,打好數據分析的基礎,是進入大數據與AI領域的必要準備。另外,針對目前海量的數據分析方法來說,可以分為數學與統計兩類:
-
數學應用
- 主要用於數字與分類資料
- 資料分類後,使用數學轉換(如transformer模型)進行層級與訓練,達到數據準確
這類分析方法如機器學習與其延伸出的系列模型、大型語言模型等。數學應用類型雖說使用了數學與數學運算方法,但其轉換與逼近的方式上未必能為數據特徵或規律建立最中的數學式結果,有助於後續的驗算或驗證。
傳統的做法上,我們會先以數理模型進行推導,得到結果。再將數據轉為符合數理模型之變數條件後,根據數理模型的數學規律進行數據分析或數據模擬,以佐證模型可以使用數據驗證。
初學者在學習這方面的內容時,要理解你是基於數學模型在做數學運算,未必是為數據的特徵或規律找出數學模型。因為以電腦科學教育的「讓數據自己說話」的概念來講,選擇何種數學模型也該由數據自己說話。另一方面,數學模型的結果會有數學式產生,如果你沒有看到程式跑出數學式結果,或者原理文章沒有提供各種數據(真實或模擬數據)的數學結果,你很可能只是在做數學運算求解,而不是為數據建模。
-
統計應用
- 可用於數字型或分類資料
- 統計應用通常指統計分析,最主要的三大功能:點估計、區間估計、假設檢定
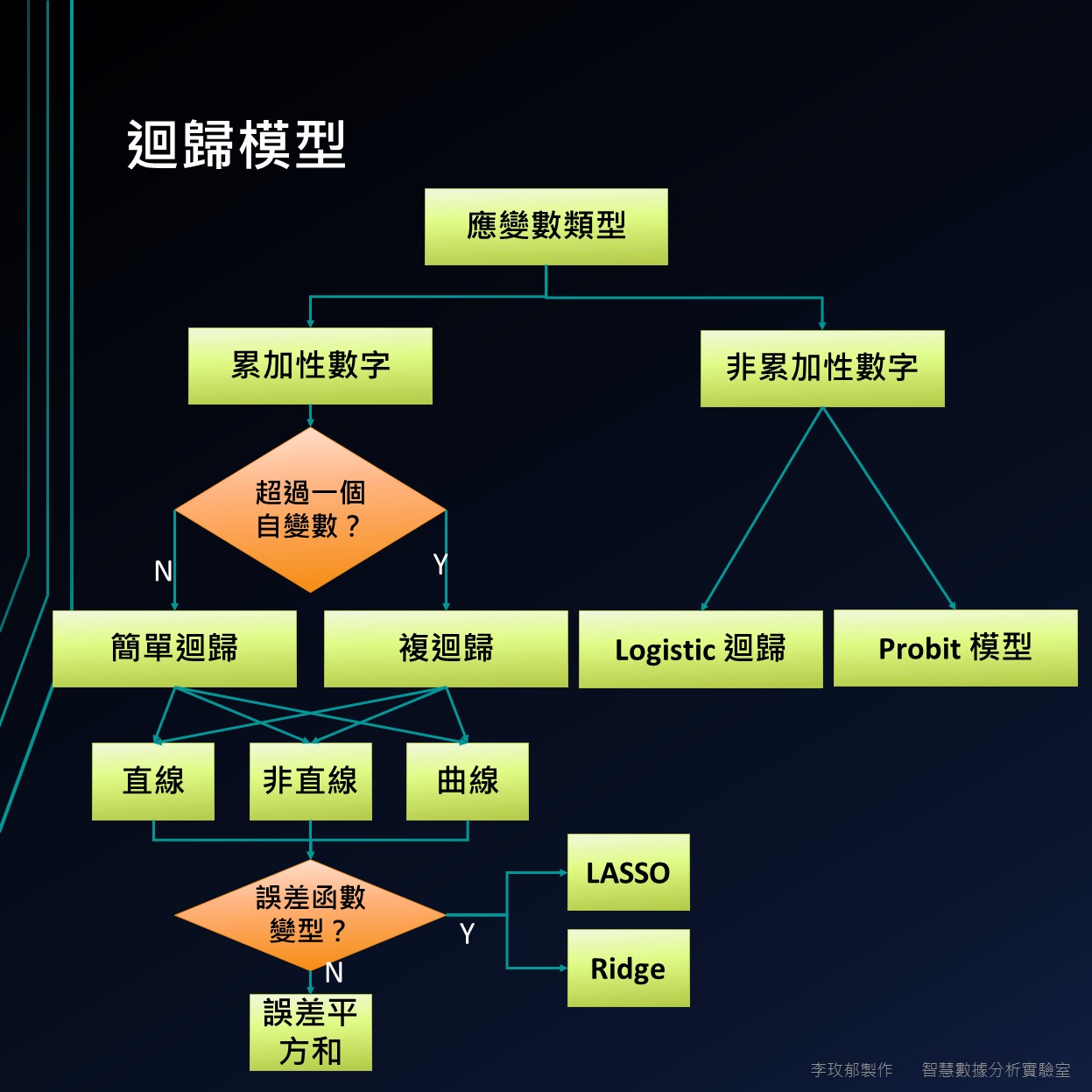
雖說迴歸分析也是統計分析的一部分,但迴歸模型前提是兩變量之間可能存在直線關係,並且某一變量可能影響另一變量。所以估計直線模型後,就對係數進行統計分析。
迴歸分析較不在意模型的解釋,而著重在係數的統計分析,所以才有所謂的統計意義。同樣大數據與人工智慧的判斷過程中會使用到假設檢定,產生統計意義。如果這部分都被省略,使用者無從看到結果,則大數據與人工智慧的結果始終都會陷在黑盒問題。
另外,迴歸模型為了達到誤差最小原則,對誤差函數進行調整,例如LASSO法、Ridge法等。
有人或許會想說怎麼沒有機率呢?如果是從數據角度去找尋數據的機率模型,那機率模型就會有數學式結果,以函數形式表示。如此來說,我們對大數據或人工智慧所需要使用的機率,可以想像不是單一值,而該是機率分配或稱為機率模型,並且有數學式結果提供驗證。
AI數據分析的建模概念,與電腦科學教育的「讓數據自己說話」理念相同。根據建模時,過去慣例由人為預設的數學模型,或樣本數量決定,轉為數據自己決定。
想做到讓「數據自己決定」的做法,需要人工智慧加入在分析方法的流程中,根據模型運算的要求,反覆運算和判斷,最終數據自己能找出最符合數據的特徵或規律的數學模型。